

Изображение создано с помощью нейросети
Когда приложение испытывает пиковые нагрузки, замедляется процесс обработки памяти и эффективность программы падает. На замедление влияет множество факторов, один из них — запуск Garbage Collector по одному из сценариев. Чтобы решить эту проблему, необходимо уменьшить потребление памяти в моменты пиковых нагрузок.
В этой статье старший инженер в группе по разработке средств управления сетевыми элементами и Go-разработчик Александр Иванов рассказывает, как изучил несколько способов реализации memory pool и провел испытания скорости работы. Вы узнаете, как уменьшить влияние GC на выполнение программы и покажу бенчмарки для разных memory pools. Объясню, какая из реализаций подойдет вашему проекту, а когда лучше не использовать memory pools и полагаться на встроенные механизмы рантайм-окружения Go.
В разработку на Go я пришел после 20 лет программирования на С++ и Assembler, где моя работа была тесно связана с мультимедиа. В этой сфере данные должны обрабатываться быстро. Представьте, сколько понадобится вычислений, чтобы проигрывать видео в разрешении 4К, декодировать и показывать 60 кадров в секунду. Поскольку я на практике знал, как такая оптимизация работает на низком уровне в программах на C/C++, мне предложили оптимизировать программу на Go.
Однако в процессе выяснилось, что оптимизация на Go сильно отличается от оптимизации на С++. В случае с С++ я мог полагаться на то, что операционная система управляет памятью и доступом к железу. В Go это работает не совсем так.
Особенность приложения, которое мне предстояло оптимизировать, заключалась в том, что 90% времени оно не требовало больших ресурсов системы, но раз в 10 минут выдавало пиковую нагрузку на подсистему памяти. Чтобы обработать приходящие по сети мегабайты, требовалось распределить в оперативной памяти много структур данных. В этот момент и происходило то, к чему бывают не готовы большинство программистов.
Известно, что Garbage Collector срабатывает в следующих сценариях:

В моем случае, когда по сети приходило много данных на обработку, GC фиксировал пиковое потребление памяти, останавливал программу, освобождал память и продолжал выполнять программу как ни в чем не бывало.
Я еще не понимал, что происходит, и первым делом я запустил профилировщик — благо, Go предоставляет прекрасные инструменты наряду с компиляторами. Так я узнал, что дело не в какой-то медленной time-critical функции, которая потребляет много CPU и прочих ресурсов. Профилировщик показал, что вся программа останавливается на срабатывании GC.
С этим нужно было что-то делать. Бесполезно было ускорять вычисления, переписывая часть кода на SIMD-инструкции и снимая нагрузку с CPU. Основным бутылочным горлышком были особенности Go-рантайма по очистке неиспользуемой памяти. Не хотелось поднимать порог срабатывания GC и настраивать рантайм не по расписанию или заставлять GC запускаться чаще или реже, чем каждые две минуты. Так можно было еще больше навредить работе программы.
Решить проблему можно, если уменьшить количество потребляемой памяти, в моменты пиковой нагрузки. Помимо банального сокращения полей в сохраняемых структурах и переноса общей повторяющейся информации в отдельные переменные, я нашел еще несколько способов, как оптимизировать работу с памятью.
Перед тем, как перейти к первому способу, рассмотрим, как Go и Garbage Collector распоряжаются памятью. Взгляните на примитивные функции GetBytes и PutBytes. Через GetBytes будем получать у рантайма некоторый слайс байт, а через PutBytes — возвращать.
Когда хочется распределить память в программе на Go, разработчики вводят переменную, а потом «забывают» про нее в расчете на то, что запустится GC и все почистит. Все с этим живут и радуются, пока не возникает необычных ситуаций, как, например, пиковые нагрузки в моем случае.
В коде GetBytes по-настоящему инициализирует слайс байт и возвращает указатель на него в вызывающий код, тогда как PutBytes лишь делает вид, что куда-то что-то возвращает. Такой подход полностью полагается на запуск GC, который определит, что на выделенный слайс больше никто не ссылается и вернет память слайса в состояние «свободен для дальнейшего использования при распределении памяти».
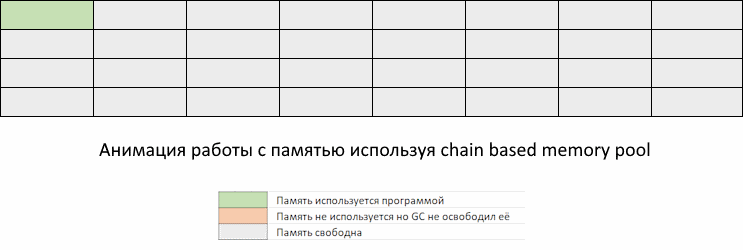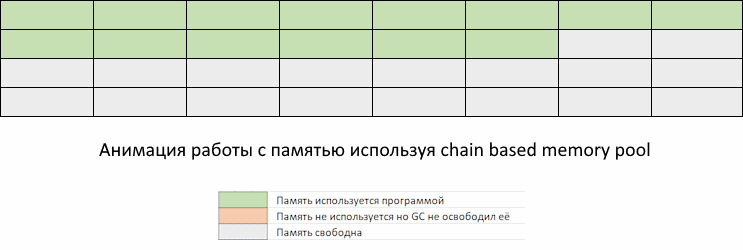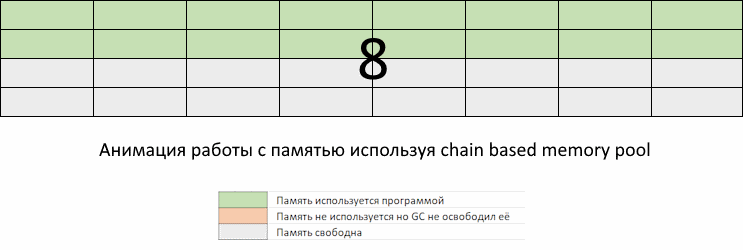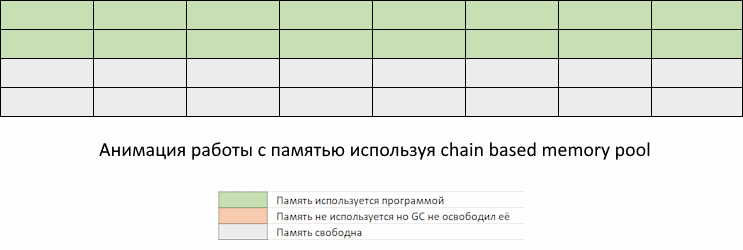
Ниже иллюстрируется нормальное поведение Go программы, без оптимизаций.
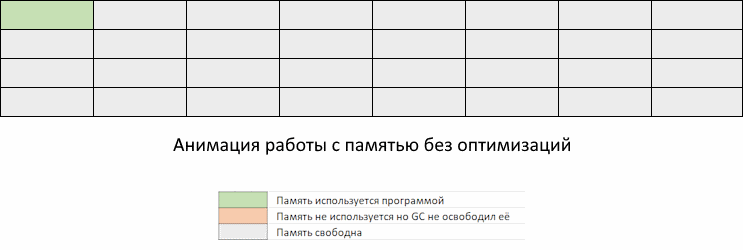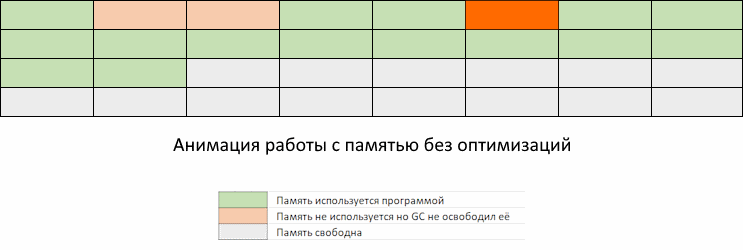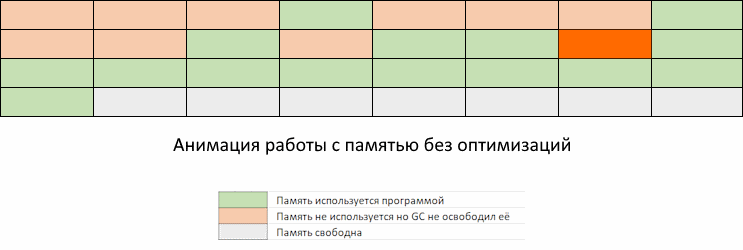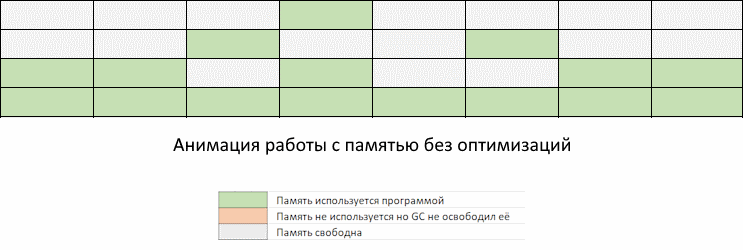
Проблема в том, что в промежуток времени между запусками GC может потребоваться выделить столько памяти, что она занятый объем памяти приблизится к пределу заданному константой GOMEMLIMIT.
Мы видим, как приложение забирает память, но GC еще не пришел, чтобы ее освободить. Память, которая освободится при очередном запуске GC, еще не доступна для переиспользования. То есть, несмотря на то, что она помечена как свободная, до запуска GC мы ее использовать не можем. Придется ждать, пока запустится GC по расписанию или по достижению GOMEMLIMIT, и вернет освобожденные участки памяти обратно в список доступных для использования.
Как правило, оптимизация работы с памятью сводится к тому, чтобы выделить определенный объем, а затем собственными средствами распределять и освобождать фрагменты под переменные. Так снимается нагрузка с GC, и он не срабатывает по достижению предела заданного константой GOMEMLIMIT. Рассмотрим некоторые способы, как это сделать.
Первый способ, который я нашел на просторах сети и успешно протестировал, заключается в том, чтобы использовать буферизованный канал для хранения распределенных фрагментов памяти. Назовем этот способ организации пула памяти Channel Pool. При такой реализации GetBytes будет дожидаться появления в канале освободившегося буфера, а PutBytes будет возвращать в канал буфер, который больше не используется:
Учитывая, что размер буферизованного канала нельзя поменять после инициализации, нужно попытаться предугадать, сколько буферов памяти будет достаточно для работы программы. Если при создании канала не удалось угадать количество требуемых буферов, то рано или поздно программа будет испытывать голод, и pool, организованный на каналах, окажется тонким местом в алгоритме.
Способ работает хорошо, но не без недостатков.
Не всегда возможно заранее угадать, сколько потребуется буферов. Можно предположить, что 10 000 будет достаточно, но рано или поздно их не хватит, а ожидание 10 001 буфера приведет к остановке алгоритма до момента, пока в канал не вернется пустой фрагмент для дальнейшего переиспользования.
Учитывая вышеперечисленное, я продолжил поиски более универсального способа, который бы не вынуждал разработчиков угадывать размер буферизированного канала.
Я продолжал искать и обнаружил структуру Pool в пакете sync. Это список, который увеличивается динамически и может хранить любую сущность, в том числе, память, выделенную в heap.
Если сделать так, что оператор new для переменной типа sync.Pool будет возвращать слайс или другую структуру большого размера, мы попользуемся и сможем вернуть в этот Pool. Если при очередном запросе на получение памяти в Pool не будет свободных мест, вызовется оператор new и выделит новый кусок. В этом плане ограничения у memory pool, организованного на sync.Pool, нет.
Фактически победили проблему, с которой столкнулись в реализации memory pool на Channel.
Однако не забывайте: если возвращенная в sync.Pool память не используется в данный момент, то GC придет по расписанию и эту память подберет. Не стоит рассчитывать, что помещенный в sync.Pool кусок памяти будет там всегда.
Поэтому не нужно хранить там данные. Некоторые разработчики попадают в эту ловушку. Они думают, что это ведь список, а раз так, то я туда сейчас положу память, а потом рано или поздно ее заберу, и все будет хорошо. Нет, так не будет. Использовать sync.Pool как кэш нельзя!
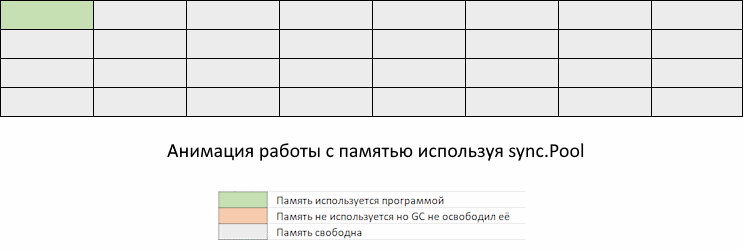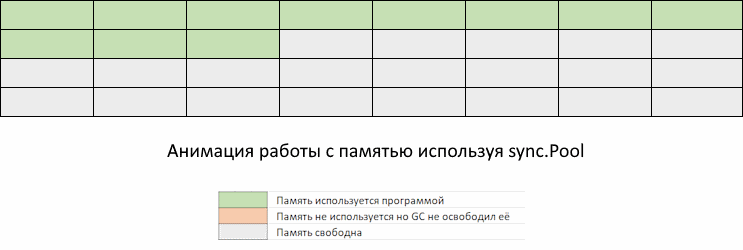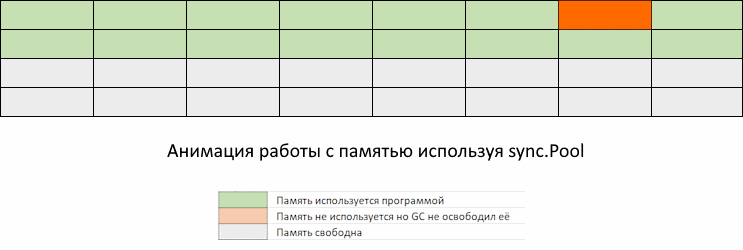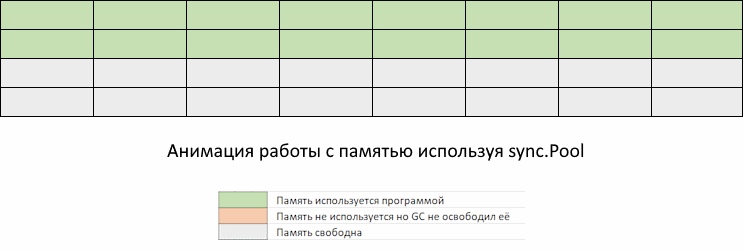
На GIF-изображении вы видите метод new, который распределяет память. Он будет вызываться каждый раз, когда в sync.Pool не хватает элементов по вашему запросу. Как мы видим, одно победили, напоролись на другое. GС все-таки «обращает внимание» на эту память.
После знакомства с sync.Pool мы перевели приложение на него. Оно заработало лучше: мы больше не упирались в предел памяти, но нет предела совершенству. Go развивается, и в языке появилась экспериментальная возможность — memory arena.
Memory arena — это кусок памяти, на который GC вообще не обращает внимания. Когда переходили на sync.Pool с памятью в heap, проблема была в том, что приходил GC и что-то подчищал. С sync.Pool с memory arena в качестве базы для памяти мы решили эту проблему, но есть нюансы.
Дело в том, что, если вы не угадали размер буфера, который запросили у memory arena, не получится просто взять и увеличить его. Вам нужно сразу загадать размер буфера, который вы будете запрашивать, чтобы любое ваше желание увеличить память вписывалось в этот размер.
Смотрите, как все просто. В принципе, никакой разницы между GetBytes и PutBytes для случаев sync.Pool в heap и в memory arena нет. Разница лишь в том, как мы реализуем метод new.
Для бенчмарков я запрашивал выделение памяти, но чтобы компилятор излишне не оптимизировал, выполнял рандомное изменение этого куска памяти, затем освобождал память в случае без оптимизации или возвращал эту память назад в memory pool.
Видим, что обычная работа с памятью без экспериментов с memory pools на порядок медленнее, чем остальные способы. Memory pool, организованный на channels, чуть-чуть медленнее, чем два других. А sync.Pool на heap и sync.Pool на memory arena показали приблизительно одинаковые результаты. На скриншоте видно, что memory arena немного быстрее, но я бы списал это на погрешность измерений.
Если посмотреть на flame-граф ниже, увидим, что способ без оптимизации съедает огромное количество памяти и многократно вызывает системные функции. Другие способы — sync.Pool на heap, sync.Pool на memory arena и channel-буферы — показывают схожие результаты по количеству вызовов функций и выделению памяти.

Если хранить в pool память как слайс, а во время использования, чтобы не выйти за его границы, менять размер слайса, в итоге слайсы могут оказаться разного размера или будут стремиться занять максимум пространства. Это касается всех memory pools, на чем бы они ни были организованы. И со временем вместо 100 буферов по 10 килобайт у вас может получиться pool из 100 буферов по 10 гигабайт. Об этом тоже всегда следует помнить, чтобы оптимизация использования памяти невольно не превратилась в ее жадное использование.
Важно различать, какую память и в каком объеме мы возвращаем в любой memory pool. То есть, если безусловно возвращать разросшийся кусок памяти в memory pool, рано или поздно это приведет к тому, что потребление памяти выйдет за ожидаемые размеры памяти.
Что делать? Нужно чуть поменять PutBytes. Эмпирическим путем выведите предел памяти для вашего проекта, который будет позволено возвращать обратно в pool. И, сравнивая размер возвращаемой памяти с этой константой, просто забывайте про слишком большие буфера, которые пытаются вернуть в pool.
Именно для этого везде в PutBytes добавлена проверка на размер возвращаемого буфера.
Кусок памяти, который не вернулся в pool, рано или поздно будет освобожден GC в общее использование. Ничего страшного не произойдет. Самое главное, что они не попадут в memory pool и не займут в итоге всю доступную память.
Чтобы выбрать реализацию, которая подойдет вашему проект, оцените, как вы работаете с памятью. Ниже я привел несколько примеров приложений, для которых подойдут разные memory pools.
Если вы не используете память активно, можно вообще не прибегать к memory management. В таком случае, максимальное, что можно сделать — провести анализ memory escape и попытаться минимизировать их количество. Распределение памяти на стеке в десятки раз быстрее, чем в heap, поэтому такой подход — наиболее эффективный для оптимизации производительности программы. При этом вы избегаете излишних манипуляций с sync.Pool или других аналогичных способов.
Если память используется редко, но распоряжаться ей хочется рационально, выбирайте Channel Pool.
Допустим, вы пишете редактор с фреймбуфером видеокадров, который используется для плавной анимации. Для такой программы хорошо подойдет memory pool, организованный на каналах, потому что вы заранее знаете размер хранилища. А мы помним, что важное условие для Channel Pool — знать, сколько буферов распределить для памяти.
Channel Pool можно использовать в программах с фрагментарной нагрузкой на память. Пиковые нагрузки такие программы испытывают, но между ними проходит немало времени. И чтобы не занимать лишнюю память постоянно, мы просто используем pool на каналах до тех пор, пока требуется память, а затем удаляем её из канали и удаляем сам канал. Память в таком случае возвращается в ведение Garbage Collector’а.
Однако существуют ситуации, когда память выделяется часто и заранее неизвестно, сколько буферов понадобится. В таких случаях рекомендую уверенно использовать sync.Pool для управления памятью. Это не приведет к проблемам с производительностью, программа будет функционировать эффективно. Главное условие — программе требуется постоянно выделять и освобождать память в не очень предсказуемых количествах.
Рассмотрим применение этого подхода на примере видеоредактора. Программа показывает пользователю видеоряд, но не в реальном времени. Это происходит, когда пользователь идет покадрово: что-то правит, заполняет timeline спецэффектами и прочее.
Для таких программ подходит sync.Pool на memory arena. Еще раз подчеркну, что memory arena хороша для случаев, когда мы не хотим, чтобы Garbage Collector подобрал эту память. А sync.Pool нас избавляет от попытки угадать заранее, сколько нам нужно буферов.
Еще memory arena подходит, когда мы точно знаем, какого размера буфер распределить. Допустим, кадр 4К — всегда кадр 4К. Не надо угадывать, распределить ли половину кадра или кадр плюс «хвостик». Поэтому memory arena — самый подходящий вариант.
Но есть случаи, которые не попадают ни под один из рассмотренных вариантов — к счастью, их не очень много. Тут включается индивидуальный подход.
Допустим, некоторые разработчики говорят: мы используем memory arena, sync.Pool и Channel Pool не подходят. В таком случае можно «попросить» из memory arena 2 ГБ памяти и организовать свой memory-менеджмент — главное подумать, как это сделать. Но, я уверен, результат оптимизации тоже получится хорошим.

