Изображение создано с помощью нейросети
Математические формулы и алгоритмы окружают инженеров повсеместно. Так, Кирилл Колодяжный, разработчик системы хранения данных в YADRO и ML-энтузиаст, столкнулся с матричными вычислениями в процессе работы со свертками на CUDA.
Кирилл — автор нескольких материалов о машинном обучении на С++. Он уже писал, как реализовать модели для распознавания лиц на фото и для поиска объекта в пространстве с помощью computer vision. В этом материале он затронет «математическую» тему и расскажет о реализации сверток: что это за операция и какие есть алгоритмы для вычисления. Приведет простые примеры с кодом, чтобы вы могли опробовать решения.
У статьи будет вторая часть: про особенности реализации одного из этих алгоритмов с использованием CUDA в рамках фреймворка PyTorch и про то, как адаптировать его под свои задачи.
Начнем с формального, но не строго математического определения.

Поскольку я буду рассказывать о свертке в машинном обучении, приведу и определение в ML-контексте.
Чаще всего свертку можно понять, как использование фильтра для обработки исходных данных или сигнала. Фильтр при взаимной корреляции не является обратным, и область пересечения между двумя функциями f и g — это взаимная корреляция.
Если рассматривать исходный сигнал как изображение, то свертку можно использовать для выделения границ. Значения фильтра, или ядра свертки, могут быть известными — как в случае с фильтром Собеля, который предназначен для выделения границ.

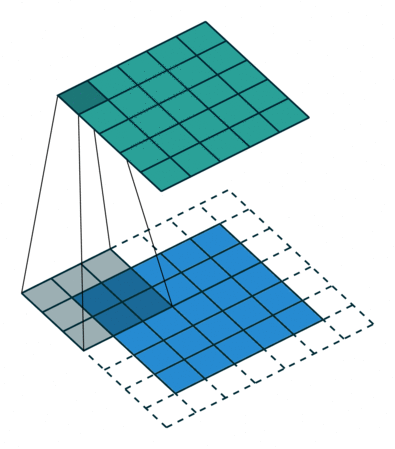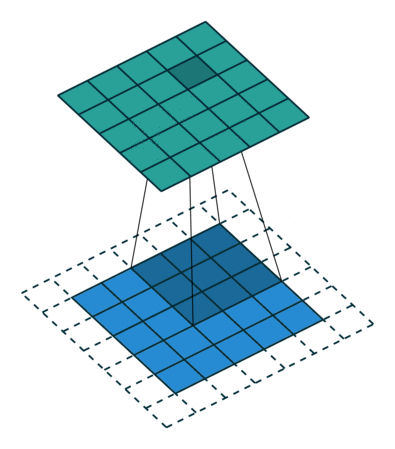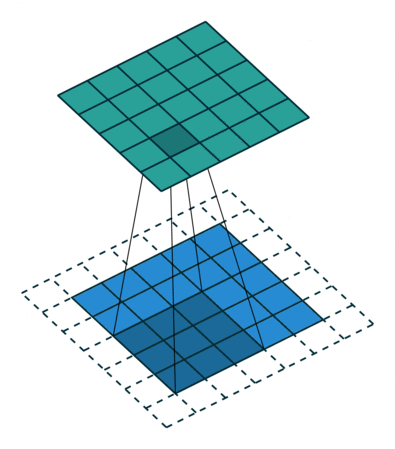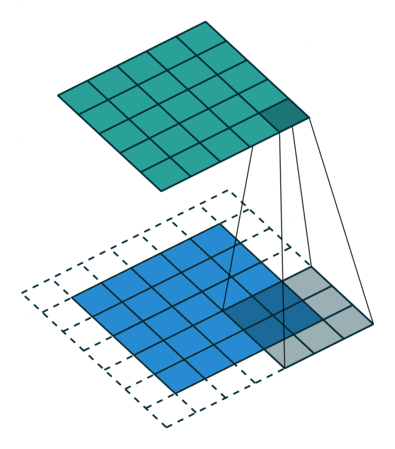
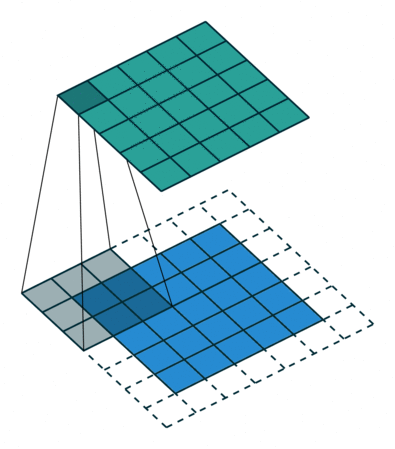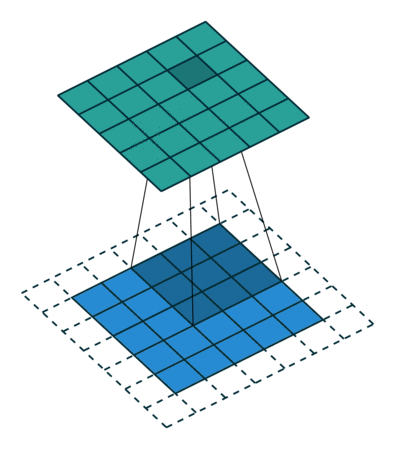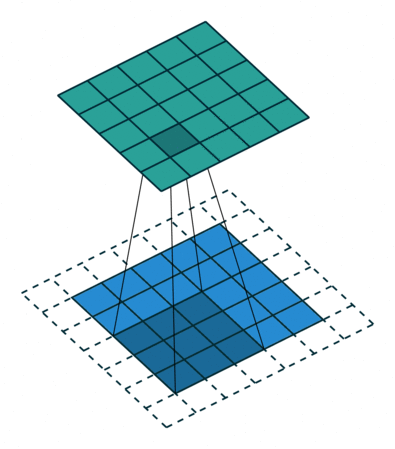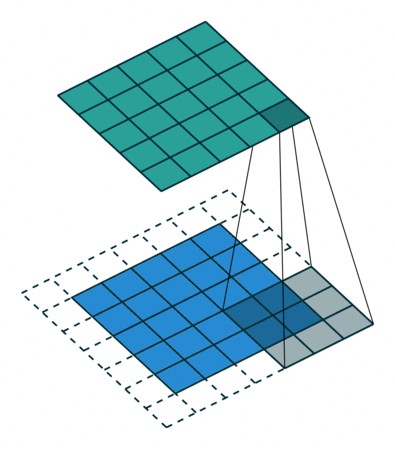
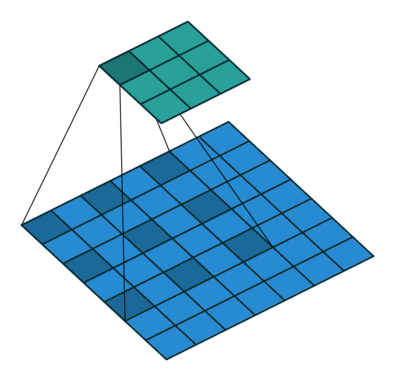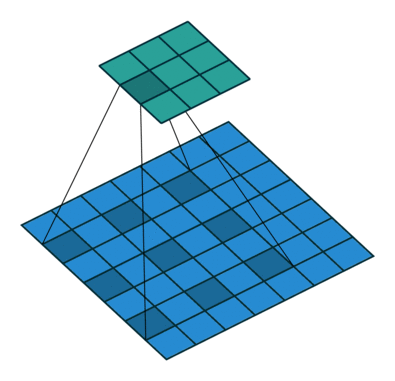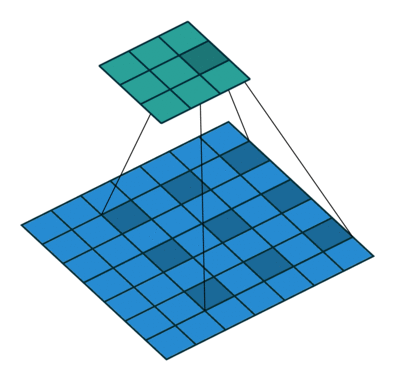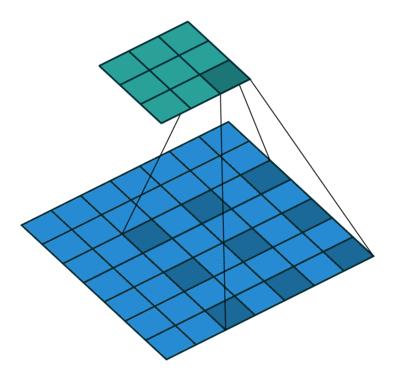
Мы проходимся двумерным сигналом по каждому элементу и прикладываем фильтр. Сначала считаем в фильтре произведение, а потом сумму элементов.
У свертки есть три характерных параметра настройки:
Padding — расширение исходного сигнала. Нужен для более осмысленной обработки краевых элементов.
Stride — шаг свертки, который показывает, через сколько элементов применять фильтр. В примере идем через два элемента.
Dilation — инструмент для реализации разреженной свертки, он задает шаг между элементами, к которым мы применяем фильтр.
Это несложная операция. Мы можем линейно применить несколько вложенных циклов для итерации по нашим параметрам: по stride, с учетом padding и размера фильтра. Допустим, для таких исходных параметров у нас получится семь вложенных циклов, внутри которых мы посчитаем произведение, а потом сумму.

Такой подход достаточно просто реализовать на CUDA. Первое, что нужно задать для реализации на GPU — это размер grid (сетки), то есть, указать количество блоков и потоков в рамках блока:
Мы пройдемся по каждой строке изображения (в статье я называю исходный сигнал изображением) и в каждом пикселе применим фильтр. Сходу можно предложить такую оптимизацию: разместить ядро в shared-памяти (локальной памяти) наших блоков, чтобы каждый раз не грузить его из глобальной памяти. Это увеличит производительность реализации.
Здесь представлен код как раз самого ядра (kernel) — функции, которая будет вычисляться в одном потоке на GPU.
Вычисляем функцию:
Синхронизация потоков нужна, чтобы перенести данные из глобальной памяти в shared-память и прекратить вычисления. Это убережет от «гонок» при обращении к еще не заполненной shared-памяти. Все потоки дойдут до этой синхронизации, а потом продолжат выполнение.
К этому моменту мы перенесем все данные из глобальной памяти в shared и дальше сможем использовать значение нашего фильтра. У нас просто есть два цикла по размерам фильтра. В примере ниже используется одно значение размерности, так как я предполагаю квадратный фильтр. И в нем точно так, как в псевдокоде выше, мы считаем произведение, прибавляем его к сумме и накапливаем результат.
Есть ли подход, который учитывает все недостатки простого метода? Давайте разберемся.
Один из альтернативных подходов — алгоритм Winograd, названный в честь автора Шмуэля Винограда. Это математик, который работал в области вычислительной сложности и анализа алгоритмов.
Сам алгоритм заключается в том, что мы переводим значение сигнала и фильтра в другое пространство — Winograd, где операцию свертки можно заменить на поэлементное умножение. Для этого нужно специальным образом подготовить матрицы преобразования.

На картинке видим такие матрицы для размера фильтра 2×2 и регион изображения 3×3.
Как работает алгоритм:
Этот подход позволяет существенно уменьшить количество операций умножения, заменив их операциями сложения. То есть амортизированная сложность с учетом того, что у нас предвычисленная матрица, существенно меньше, чем у наивного подхода.
Однако тоже есть определенные ограничения:
Следующий алгоритм для быстрого вычисления свертки — быстрое преобразование Фурье. Суть та же:
Это можно изобразить следующей схемой:

Слева на картинке изображен фильтр. При использовании подхода с FFT нам нужно добавить padding и к исходному сигналу, и к фильтру, чтобы согласовать их размерности. После чего сделать преобразование фильтра в частотное пространство. И дальше двигаемся окном по исходному сигналу, делаем FFT-преобразование, производим умножение с фильтром и формирование выхода.
Надо сказать, что подход работает намного быстрее, чем наивная реализация. Вычислительная сложность алгоритма — O (N2 log(N). Но есть ограничение: он будет требовать намного больше памяти. Это связано с тем, что сам преобразованный сигнал в преобразовании Фурье будет занимать больше памяти. В зависимости от выбранного подхода мы должны идти окном по исходному сигналу с перекрытием.
Таким образом, у нас будут получаться дополнительные области памяти, ненужные для формирования выходного сигнала, но нужные для работы алгоритма.

Следующий подход основан на быстром вычислении операции GEMM (General Matrix Multiplication):
𝐶←𝛼𝐴𝐵+𝛽𝐶
Это операция — одна из функций библиотек для линейной алгебры, реализующих интерфейс BLAS (Basic Linear Algebra Subprograms). Представляет собой взвешенное произведение матриц со сложением в какой-то аккумулятор (третью матрицу), также умноженное на коэффициент. В целом вычислительная сложность умножения матриц — это O (𝒏𝒎𝒑) или O (𝒏^𝟑), если у нас квадратная матрица.
Однако есть на данный момент алгоритмы и побыстрее. По-моему, самый лучший результат сейчас — это n в степени примерно 2,4. Что еще хорошо: у операции матричного умножения высокая арифметическая интенсивность:
Арифметических операций намного больше, чем обращений в память, — значит, мы можем потенциально хорошо ее распараллелить.
Эта операция реализована во многих библиотеках — от тех, которые работают на CPU, до GPU и специальных вычислителей. Это OpenBLAS, cuBLAS, Cutlass, Intel MKL, rocBLAS. Она подходит под разные программные фреймворки и аппаратные реализации.
Суть распараллеливания заключается в том, что мы разделяем операцию умножения на отдельные блоки.

Перемножение строки и столбца делим на отдельные блоки, и вот эти маленькие матричные умножения разносим на разные потоки вычисления. В рамках этих потоков мы также можем использовать специальные, хорошо оптимизированные инструкции для вычисления. Например, тензорные ядра и операции MMA (Matrix multiply-add) или Fused multiply-add-операции.
Чтобы использовать операцию GEMM для вычисления свертки, нужно преобразовать как изображение, так и фильтр в формат, подходящий для матричного умножения. Перемножить напрямую мы их, конечно, не можем. Существует подход, называемый Image to column (im2col) или Volume to column (vol2col), который описывает, каким образом нам преобразовать исходное изображение в подходящую матрицу для операции GEMM.
Здесь представлен результат преобразования изображения 3×3 с padding = 1 в такую матрицу 9×9:

Мы видим, что многие элементы здесь повторяются. Это происходит из-за того, что фильтр движется скользящим окном и вычисление производится с этими же элементами.
Отсюда следует одно из основных ограничений этого алгоритма: он требует достаточно много памяти из-за повторяющихся элементов построения большой матрицы. Однако это компенсируется очень быстрым вычислением операции GEMM. Плюс алгоритм подвержен «проклятию размерности».

Если мы увеличим количество, допустим, слоев, у нас будет трехмерная свертка. А если еще используем достаточно много батчей, матрица будет пропорционально сильно расти.
Но есть способ решения проблем с потреблением памяти — мы не обязаны хранить всю эту большую матрицу в памяти.
Существует подход, продолжающий GEMM, — обычно его называют Implicit GEMM. Суть в том, что мы не вычисляем сразу всю большую матрицу свертки. Мы ее будем вычислять по мере работы потоков, динамически загружать нужные нам блоки в shared memory и потом эффективно их вычислять. Этот подход более подробно разберем во второй части.
Наивный подход, несмотря на его недостатки, используется нередко. Он реализован в cuBLAS и будет работать для небольших размерностей ядер и данных.
Алгоритм Winograd очень эффективный, но используется для маленьких ядер, так как для больших размеров ядер матрица для преобразования будет сильно расти. Плюс у подхода часто ограниченный набор параметров для свертки.
Алгоритмы, основанные на преобразовании Фурье, подходят для больших ядер, для больших размерностей входных данных, но требуют достаточно много памяти.
GEMM, по сути, то же самое, что FFT. Работает с любым набором параметров, с любыми размерностями, если вам хватает памяти. Самое распространенное применение — вариант с Implicit GEMM, потому что он работает достаточно гибко, обрабатывает и маленькие, и большие, и средние размеры, требует не так много памяти.