

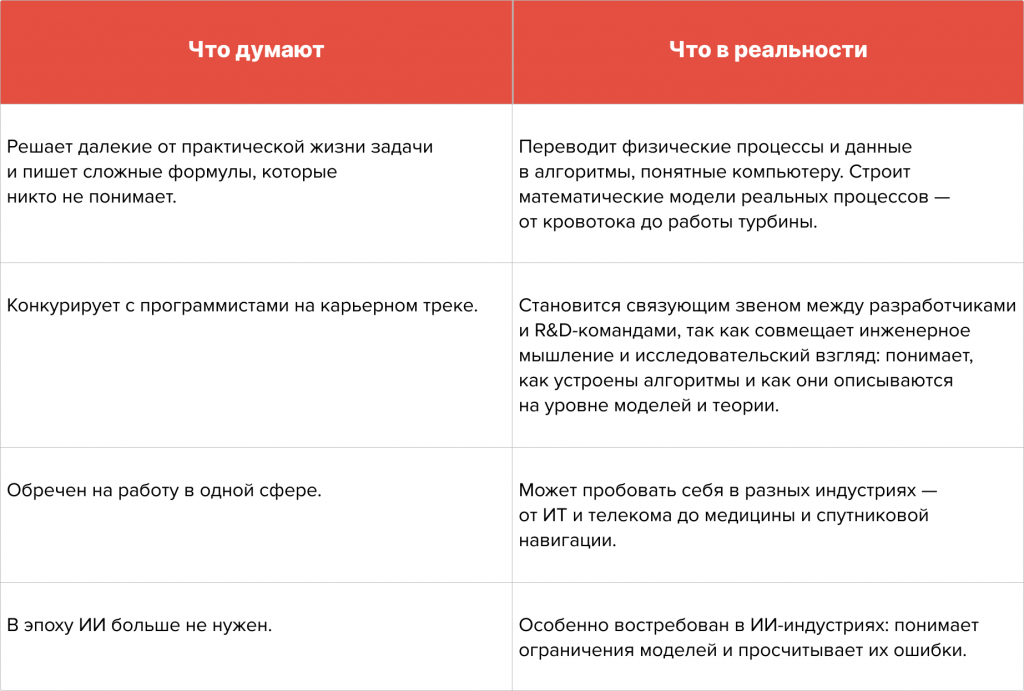
«Высшая математика — это про абстракции, которые не нужны настоящему инженеру. Зачем зубрить сложные алгоритмы в эпоху ChatGPT и Claude Code?» Так думают многие студенты, и совершенно напрасно, считает эксперт по разработке программного обеспечения в YADRO Валерия Пузикова.
Валерия работала над разными инженерными проектами — от создания алгоритмов для медицинских приборов до прогнозирования аварий на электростанциях. Она на собственном опыте убедилась, что математика помогает не только быстрее закрывать сложные технические задачи, но развивать аналитическое мышление, а еще находить нестандартные решения. О том, как фундаментальные знания помогают в «реальной» инженерии и гигиене мышления, — в трех кейсах из ее практики.
- в каких сферах инженерии востребовано математическое образование
- зачем инженеру понимать границы применимости алгоритмов
- как декомпозиция повышает точность цифровых моделей
- почему большие языковые модели «галлюцинируют» на оптимизированном коде
Почему математика — это про широкий карьерный выбор
Стереотип о том, что высшая математика нужна только в аудиториях и научных статьях, жив до сих пор. Многие считают, что для успешной инженерной карьеры важнее освоить конкретные инструменты и технологии, а фундаментальные дисциплины остаются где-то на втором плане.
О бесполезности высшей математики для «настоящей карьеры» я слышу с самого детства. Даже мои родители когда-то скептически отнеслись к идее поступить в Бауманку на «Прикладную математику» — не понимали, где я потом смогу работать по специальности.
Практика показала, что скепсис был напрасным. После окончания института я поработала прикладным математиком в медицине, энергетике, AR/VR, аэрогидродинамике, маркетинге, ИИ и анализе данных. И такой карьерный набор — не исключение из правил, а нормальная траектория. Почему? Это предполагает сама суть профессии.
Математик в прикладной инженерии: чем занимается
Прикладной математик относительно легко может сменить предметную область, поскольку везде действуют одни и те же принципы формализации, построения моделей, проверки гипотез и оценки погрешности.
Казалось бы, что общего у симуляции одежды и волос мультяшного персонажа в AR/VR или расчета обтекания крыла самолета в вычислительной аэродинамике? Для математика ответ очевиден: механика сплошной среды и численные методы.
Это правило действует в самых разных областях. Например, еще вчера вы разрабатывали алгоритмы для анализа биомедицинских сигналов, а сегодня уже увлеченно разбираетесь в АСУТП на электростанции, чтобы разработать новый алгоритм предсказания давления в критически важных узлах.
И всё это потому, что математика дает вам не привязку к какой-то конкретной предметной области, а способность разбираться в сути физических или технологических явлений, преобразовывать их в математическую модель, строить алгоритм численного метода и его программную реализацию.
Прикладной математик в любой предметной области задает одни и те же «скучные» вопросы: «Где границы модели? При каких параметрах она перестает работать? Воспроизводится ли результат на других данных?» Именно такая гигиена мышления спасает от катастроф в реальных задачах, будь то неверный медицинский диагноз, авария на электростанции или разрушение конструкции на испытаниях.
Как она помогает на практике — разберем на примере кейсов из моей собственной работы.
Кейс 1. Программа для определения глубины залегания пород

Ко мне как к программисту обратилась команда физиков. Они разрабатывали программу для сейсморазведки — метода, который помогает изучать строение земных недр по отражению звуковых волн. Если совсем упрощенно, задача состояла в том, чтобы по сигналу, вернувшемуся из-под земли, понять, на какой глубине находятся разные слои пород и из чего они состоят.
Проблема же следующая: за время пути сигнал искажается и смешивается с помехами, поэтому компьютеру приходится восстанавливать исходную картину по неполным и «зашумленным» данным. .
Как к задаче подходят нематематики
Команда была уверена, что проблема именно в программе, ее неоптимальной реализации, и совершенно не сомневалась в правильности своих эмпирически подобранных параметров. Они исходили из физического смысла этих параметров, подбирали коэффициенты экспериментально, опираясь на реальные записи с полевых измерений.
И их логика была понятна: «Мы знаем физику процесса, данные настоящие, алгоритмы реализованы корректно, значит, проблема в коде. Надо оптимизировать вычисления, может быть там есть лишние циклы или что-то можно распараллелить».
Они понимали, что могли сделать что-то не так, как программисты, но даже не допускали мысль, что в численном методе параметры нужно подбирать не только физически, но и математически.
Как к задаче подходят математики
Меня насторожило не то, что программа работала медленно. Гораздо интереснее было другое: самым медленным оказался численный метод, который по теории должен был сходиться к решению быстрее остальных. А это уже выглядело как тревожный сигнал.
Если метод, который должен быстро находить ответ, внезапно начинает работать дольше всех, вполне возможно, что он вообще не движется к правильному решению.
Проблема была в самой природе задачи. Восстановление сигнала относится к так называемым обратным задачам: мы пытаемся по косвенным и частично искаженным данным восстановить исходную картину. Такие задачи известны своей численной неустойчивостью.
Достаточно небольшой ошибки во входных данных или неудачно выбранного параметра регуляризации — специальной математической настройки, которая помогает отделять полезный сигнал от шума, — и решение начинает «жить своей жизнью».
Вместо того чтобы постепенно приближаться к правильному ответу, алгоритм может застрять в промежуточном решении, которое кажется хорошим только на первый взгляд, или начать бесконечно блуждать среди множества вариантов. Снаружи это выглядит как долгий и тяжелый расчет, а на деле компьютер просто выполняет тысячи лишних итераций, не становясь ни на шаг ближе к результату.

Мы решили не спорить, а сели вместе и построили графики сходимости. Картина стала очевидной: итерации вообще не приближались к решению, они либо выходили на «плато», далекое от точного решения, либо полностью расходились.
Иными словами, это был не баг в коде и не «неоптимальная программная реализация», а банальный выход за границы сходимости итерационного метода из-за очень неудачно выбранных параметров.
Когда мы заменили «подобранные эмпирически» параметры на математически обоснованные и правильно «подкрутили» регуляризацию, все алгоритмы не только дали предсказанную теорией точность, но и радикально ускорились.

Что в итоге:
- математическая модель показала, что код был изначально рабочим и никакая программная оптимизация не понадобилась;
- расчет, который раньше длился часами, стал укладываться в минуты;
- геофизики получили адекватную картину подземных слоев.
Кейс 2. Алгоритм прогнозирования давления в системе

На одной из электростанций заметили, что отдельные узлы стали чаще выходить из строя или демонстрировать признаки ускоренного износа. При этом система автоматического мониторинга не предупреждала о проблемах заранее.
Цифровой двойник установки был разработан несколько лет назад и представлял собой единую модель, обученную на исторических данных.
Главный инженер решил, что модель нужно дообучить на свежих данных, а возможно и заменить алгоритм предсказания давления в критически важных точках на более современный. С такой задачей ко мне и обратились.
Как к задаче подходят нематематики
Инженеры на объекте исходили из, казалось бы, здравой логики: чем больше данных и чем сложнее модель, тем точнее прогноз. Опираясь на этот принцип, они собрали всю доступную телеметрию и обучили одну глобальную модель установки, которая показывала отличные результаты на исторических данных.
А когда появились «слепые» отказы, первой реакцией было предположить, что модель перестала справляться с новыми условиями эксплуатации или просто устарела. Поэтому обсуждались вполне очевидные меры: добавить свежие данные, усложнить модель, подобрать более современный алгоритм.
При этом никто не поставил под вопрос базовую идею проекта — что всю сложную установку можно достаточно точно описать одной общей моделью. Проблему искали в качестве инструмента, а не в том, правильно ли вообще выбрана схема описания объекта. Но именно здесь и скрывалась ключевая ошибка.
Как к задаче подходят математики
Для него электростанция — не монолитный объект и не «черный ящик», а граф взаимосвязанных узлов, каждый из которых подчиняется своим физическим закономерностям.
В одних узлах процессы протекают медленно и почти линейно — то есть изменение одного параметра приводит к примерно пропорциональному изменению другого. В других важна динамика системы во времени: давление, температура или расход постоянно меняются и влияют друг на друга. Такие процессы часто описываются системами дифференциальных уравнений, которые позволяют моделировать их поведение.
Наконец, есть узлы с выраженными стохастическими колебаниями. Это случайные отклонения, вызванные шумами датчиков, изменением нагрузки или другими трудно прогнозируемыми факторами. Для них уже нужны статистические модели, работающие с вероятностями и неопределенностью.
Единая модель вынуждена усреднять эти разнородные процессы, теряя чувствительность к аномалиям в конкретном узле. Получается как в том анекдоте про среднюю температуру по больнице: у одних пациентов лихорадка, у других уже остывают пятки, а в среднем у них — эталонные 36,6.
Так же и здесь: на номинальных режимах такая «усредненная» модель еще держится, но стоит системе выйти за пределы привычных условий, как она начинает опираться на усредненные закономерности там, где они уже не действуют. В результате на мониторе диспетчера всё по-прежнему остается в «зеленой зоне», хотя отдельные узлы фактически переходят в предаварийный режим. Ошибка накапливается, а система этого не видит.
Что мы сделали в итоге? Начали не с замены алгоритма, а с декомпозиции системы: разделили узлы на группы в зависимости от типа протекающих в них процессов, а затем для каждой группы подобрали модель, которая соответствует физике процесса и корректно работает в своих границах применимости.
Где-то оказалось достаточно простой аппроксимации — математического приближения, хорошо описывающего наблюдаемую зависимость. Где-то потребовались модели на основе дифференциальных уравнений, позволяющие учитывать динамику процесса и контролировать устойчивость расчетов. А для узлов с высокой неопределенностью и случайными колебаниями мы использовали вероятностные модели, которые не только дают прогноз, но и учитывают историческое распределение значений.

После этого жизнь диспетчеров заметно оживилась. Они начали получать сообщения от системы: «В узле Х прогнозируется экспоненциальный рост давления с аварийным остановом через Y часов». То есть как и в первом кейсе, проблема оказалась совсем не там, где изначально думали: модель не устарела, а просто показывала слишком усредненную картину.
Что в итоге:
- вместо одной «универсальной» модели получился набор специализированных моделей;
- каждая модель стала отвечать за свой участок системы и лучше отражать его реальное поведение;
- повысилась чувствительность к локальным отклонениям системы;
- на электростанции стали раньше выявлять признаки потенциальных отказов.
Кейс 3. ИИ для автоматизации

Сегодня вокруг ИИ сформировались два лагеря, и оба регулярно наступают на одни и те же грабли. Одни относятся к модели как к «волшебной таблетке» и ждут от нее готовых ответов на любые вопросы. Другие сталкиваются с парой неудачных результатов и тут же записывают технологию в бесполезные.
Мой знакомый разработчик хотел использовать доступные в своей команде большие языковые модели для проверки программного кода в репозиториях с высокооптимизированными алгоритмами, написанными на C и ассемблере, где важна буквально каждая инструкция.
Результат его сильно разочаровал: модель находила «ошибки» там, где их не было, но пропускала реальные баги, а в оптимизированных циклах и вовсе «несла откровенный бред». Вердикт напрашивался сам собой: «Доступные ИИ-модели для код-ревью в нашей области неприменимы».
Как к задаче подходят нематематики
Разработчик подходил к LLM как к почти разумному коллеге: раз она обучалась на миллионах репозиториев, то должна «понимать» код и отличать хорошее от плохого. И оценивалась она по простой шкале: либо справляется со всей задачей проверки кода, либо полностью бесполезна.
Когда начали появляться ошибки, первым объяснением стало не «возможно, мы неправильно используем инструмент», а скорее «модель еще сырая, технология пока не готова». Такой подход напоминает попытку забить шуруп молотком: инструмент хороший, но применен не по адресу.
При этом легко забыть, как устроены современные языковые модели. Даже самые продвинутые LLM не «понимают» код в человеческом смысле слова. С математической точки зрения это очень сложные статистические модели, обученные минимизировать функцию ошибок на огромных массивах данных и предсказывать наиболее вероятные последовательности токенов.
Их сильная сторона — поиск закономерностей в данных, но это не то же самое, что инженерное понимание корректности алгоритма или логики программы.
Как к задаче подходят математики
Математик смотрит на LLM и видит в ней не «разум», а гигантский аппроксиматор, обученный минимизировать функцию потерь — по сути, «энергию» несоответствия обучающим данным.
Здесь закон един: все хотят минимизировать свои энергозатраты, и искусственный интеллект не исключение. Промпт для такой модели — это возмущение в многомерном пространстве параметров. И нейросеть реагирует на него единственным известным ей способом: она «скатывается» в ближайший минимум этой самой энергии, порождая наиболее вероятное (с точки зрения обучающей выборки) продолжение текста. Математик об этом не забывает.
Он знает, что никакого анализа корректности в инженерном смысле у нейросети нет — есть статистическая интерполяция. И чем больше модель «узнала» при обучении и смогла «сохранить в своих весах», тем точнее будет эта интерполяция.

Именно поэтому в сложных, нестандартных или узкоспециализированных ситуациях — например, при анализе плотно оптимизированных участков кода — модель может выйти за пределы области, где ее аппроксимация остается надежной и начать «галлюцинировать». Она не ошибается в человеческом смысле слова и не пытается никого обмануть: по-прежнему добросовестно строит наиболее вероятное продолжение текста. Просто в этой области статистические закономерности, на которые она опирается, уже плохо соответствуют реальной структуре кода.
Это тот же феномен, который мы наблюдали в предыдущем кейсе с цифровым двойником. Модель продолжает работать по своим правилам, но оказывается за пределами области, где ее прогнозам можно доверять. Разница лишь в том, что там речь шла о физических процессах, а здесь — о статистической модели языка.
И, как и в предыдущем кейсе, верным подспорьем математика оказывается декомпозиция. Когда я ее осуществила, то выяснилось, что доступная разработчику модель действительно плохо выявляет сложные алгоритмические ошибки в оптимизированных циклах, поэтому такие проверки поручать ей не имело никакого смысла.
Зато она быстро и довольно надежно находила нарушения в документации и код-стайле, синтаксические проблемы, несогласованности между модулями, опечатки в названиях и другие рутинные дефекты. В результате команда составила четкий промпт, ограничив область поиска именно такими классами ошибок, и модель взяла эту часть проверки на себя.
Опытный разработчик потратил бы на их поиск много внимания и все равно мог бы что-то пропустить из-за усталости. Теперь он может сконцентрироваться на проверке сложной логики и математики, а в рутинных проверках довериться этой локальной модели.
И, что важно, разработчик перестал разочаровываться в инструменте, потому что осознал его границы применимости и согласился, что их наличие — это нормально. Так же, как не ждать от кофеварки, что она заодно выжмет сок из лимона.
Что в итоге:
- большая языковая модель «реабилитирована» как эффективный метод;
- определены «зоны ее ответственности», вне которых задачи выполняются с помощью более точных методов;
- разработчики обрели дополнительную уверенность в своих инструментах.

Как математическое образование расширяет инженерный майндсет
О чем говорят все эти истории? Математика — это не про «скучные цифры», а про формирование особого стиля мышления, с которым ты начинаешь «видеть», где инженерная идея перестает работать.
Почему это важно? Сегодня цифровые модели используются практически в любой инженерной области. И инженер без серьезной математической подготовки сталкивается с одной и той же проблемой: он не видит границы адекватности таких моделей. Более того, не всегда осознает, что эти границы вообще существуют.
Отсюда и ситуации: вводишь данные, программа строит красивый график, а в реальности конструкция оказывается неработоспособной. Или наоборот — отказываешься от перспективного решения только потому, что модель выдала «полную дичь» в условиях, для которых она изначально не предназначалась.
Именно от таких просчетов и защищает фундаментальное образование. Оно дает не просто запись в дипломе, а привычку задавать правильные вопросы:
- какие допущения лежат в основе модели;
- где заканчивается область ее применения;
- насколько можно доверять полученному результату.
Прикладных математиков учат не только строить строгие теоретические доказательства. Их учат переводить физические и технические задачи на язык математики:
- выбирать адекватную математическую модель;
- подбирать численный метод;
- оценивать погрешности;
- реализовывать всё это в виде работающего программного кода.
Поэтому тем, кто, как когда-то и я, выбирает будущую профессию, но сталкивается со скепсисом со стороны, я бы посоветовала не отказываться от этого пути только из-за чужих опасений. Если вас действительно увлекает математика, стоит дать себе шанс.

Как попробовать профессию «на вкус»
Но прежде чем выбирать вуз, честно ответьте себе: вас «драйвит» красота абстрактных построений или желание видеть, как формулы превращаются в предсказанный результат на графике? Одно без другого не существует, но именно это соотношение во многом определяет, станет ли ваше образование фундаментом для научной карьеры, инженерной практики или позволит свободно переходить между разными отраслями, как это получилось у меня.
Затрудняетесь с ответом на вопрос выше? Отличный способ попробовать профессию «на вкус» — прикладные хакатоны и проектные школы. Сегодня это не только олимпиады по решению задач, но также командные соревнования по анализу данных и математическому моделированию.
Многие компании — от IT-корпораций до нефтяных гигантов — сегодня проводят открытые стажировки для студентов, где можно решать реальные кейсы. Это отличный опыт, позволяющий понять, к чему больше лежит душа: к визуализации, алгоритмам физическим процессам или к работе с большими данными.

Второй принципиальный момент — наставник и среда. Математику можно изучать и самостоятельно, но без ментора с практическим опытом этот путь будет дольше и хаотичнее. Именно поэтому выбор вуза так важен.
Хороший вуз — это не только диплом. Это прежде всего среда: люди, с которыми можно спорить и обсуждать идеи, преподаватели и инженеры, которые вовлекают в реальные задачи. Именно в такой среде я когда-то поняла, что профессия прикладного математика гораздо шире, интереснее и разнообразнее, чем представлялась мне, когда я поступала.
Выбираем вуз — на что обратить внимание
Независимо от того, какое «крыло» математики — теоретическое или прикладное — вы выберете, набор вступительных экзаменов стандартный:
- профильная математика (на некоторых программах — дополнительное вступительное испытание),
- русский язык,
- информатика,
- возможно, физика (зависит от вуза).
Сегодня математические специальности в том или ином виде есть, пожалуй, почти во всех крупных университетах. Если вуз технический, то, как правило, акцент делается на прикладной математике — именно о таком направлении я рассказывала выше. Если вам близок этот путь, смело могу рекомендовать свою родную кафедру ФН-2 «Прикладная математика» МГТУ им. Н. Э. Баумана.
Если же больше привлекает построение новых математических теорий, то, исходя из моих наблюдений, стоит присмотреться к мехмату МГУ и аналогичным факультетам. А для тех, кто мечтает не только применять, но и создавать новые модели искусственного интеллекта, есть новость: в этом году МГУ открывает набор на новый факультет искусственного интеллекта.
Привлекает последняя часть триады «модель — алгоритм — программа«? Тогда обратите внимание на ИТММ ННГУ им. Н. И. Лобачевского и факультет вычислительной математики и кибернетики (ВМК) МГУ им. М. В. Ломоносова. Оба, по моим наблюдениям, дают очень сильную подготовку в этом направлении.

Но главное здесь — не конкретный вуз и не конкретная кафедра, а то, насколько вы сами «горите» математикой, моделями и кодом, как много читаете статей о новых численных методах за пределами университетской программы и насколько готовы постоянно учиться.
Как ни парадоксально, мой самый эрудированный в области численных методов коллега по образованию вообще не математик — он окончил физический факультет МГУ и защитил диплом по квантовой механике.
Поэтому, даже если вы уже учитесь в университете совсем на другой специальности, а после прочтения этой статьи вам захотелось в эту свободолюбивую и точную прикладную математику, не расстраивайтесь — еще ничего не потеряно. Было бы желание.
У меня оно сохраняется до сих пор. Для меня математика — не только работа, но и любимое хобби, своеобразная медитация и «перезагрузка». Только не через эмоции, а через структуру.
События в жизни и в мире вокруг могут быть непредсказуемыми и внезапными, а в мире формул всё подчиняется строгим законам. И у каждой проблемы есть свое стройное решение.
Причем неважно, идет ли речь об износостойкости инфраструктуры на электростанции или о сложной физике движения одежды и волос цифрового аватара — еще одном проекте, которым мне довелось заниматься благодаря математике.


В математике всё честно и точно: итерационный метод либо сходится, либо нет. Здесь нет человеческого фактора и двойных стандартов. И в то же время любая ошибка — не приговор (по крайней мере, пока решение не ушло в эксплуатацию), а всего лишь неверный шаг в вычислениях или баг в коде.
Всегда можно вернуться на шаг назад, скорректировать алгоритм или исходную модель и получить надежный инструмент для расчетов. И, наверное, именно за это я так люблю свою профессию.



