

Изображение создано с помощью нейросети
Продолжим разговор про свертки в ML-обучении на C++. Мы уже обсудили, какие есть подходы к реализации сверток: Winograd, быстрая реализация Фурье, GEMM и Implicit GEMM, а также простой подход.
Теперь поговорим, как в одном моем проекте нужно было расширить функциональность PyTorch для работы со свертками размерностью больше трех, а потом использовать их в обучении моделей. Сначала рассмотрим, какие ограничения на выбор алгоритма накладывает возможность обучения моделей, а затем изучим два подхода к реализации свертки и адаптируем их к нашей задаче.
И зачем вообще в ML рассматривать алгоритмы свертки для больших ядер? Если вы работали со сверточными сетями, чаще всего видели свертки 3×3, 5×5 и 7×7. Они используются при запуске моделей, то есть при прямом проходе.
Большие ядра нужны в обучении сетей: во время backpropagation и вычисления градиента свертки. Дело в том, что градиент свертки вычисляется тоже через свертку:

Или в виде формул для градиентов фильтра и сигнала:

Допустим, изображение большое, а мы прошли по нему ядром 3×3. Результат получился достаточно большой, так как ядро было маленькое и, соответственно, результат мало изменился в размерах. При обратном проходе нам придется умножать на градиент результата по следующей схеме:


Причем умножать нужно два раза — для вычисления градиентов ядра и для исходного сигнала. Поэтому часто на forward pass используются одни алгоритмы — допустим, тот же Winograd. А вот для «обратного пути» потребуются уже другие алгоритмы, которые эффективно работают с большими размерностями ядер.
Например, 3D-сверткой это может быть обработка RGB-изображений, то есть у нас есть три канала и 3D-фильтр (хотя для изображений обычно обходятся тремя 2D-фильтрами).

Или у нас есть облако точек — это три координаты, плюс может быть еще цвет и дополнительные характеристики.

Четырехмерную свертку сложнее визуализировать. Мы можем интерпретировать четвертое изображение как время при обработке видео: четырехмерные тензоры, которые состоят из трехмерных, допустим, по три канала.

Сейчас в PyTorch и других фреймворках максимальная размерность свертки — трехмерная.
Это, в частности, обусловлено тем, что размер сетки (grid) вычислений в различных API разработки для GPU — 3D. На самом деле многомерную свертку можно реализовать через рекурсию применения сверток меньшей размерности. Для этого есть готовые библиотеки, например эта. Но при таком подходе активно расходуется память и есть вопросы к производительности, поэтому мы с командой решили его усовершенствовать.
У нас было требование использовать PyTorch, поэтому мы не использовали OpenCL и Vulkan, потому что самый ходовой бэкенд в PyTorch — это CUDA с использованием библиотек cuDNN или cuBLAS. В последнее время еще используется Cutlass и Triton. А вот бэкенды на OpenCL есть только от независимых авторов. Бэкенд на Vulkan развивается достаточно динамично, но он нестабильный и поддерживает далеко не все операции.
Начнем с инструментов для вычисления свертки в PyTorch.im2col.
По дефолту PyTorch использует бэкенд, основанный на cuDNN. СuDNN предоставляет функцию для вычисления как прямого прохода свертки cudnnConvolutionForward, так и обратного. К тому же он позволяет выбирать алгоритм для конкретной операции:
Есть два основных подхода для выбора алгоритма, которые предоставляет cuDNN.
Есть функция cudnnFindConvolutionForwardAlgorithm, которая позволяет подобрать алгоритм в зависимости от ваших требований. Если мы хотим подобрать самый быстрый алгоритм, мы указываем нужный флаг CUDNN_CONVOLUTION_FWD_PREFER_FASTEST и функция подберет нужный алгоритм. Но не забывайте, что может подобраться алгоритм, например GEMM, который требует много памяти.
Поэтому следующая операция после подбора алгоритма в данном случае — определение количества дополнительной памяти. Это делается тоже через API cuDNN, через получение workspace_size, после чего мы его аллоцируем и используем уже при вызове соответствующей свертки. Размер памяти будет зависеть от размеров входных данных, фильтра, параметров: stride, padding, dilation.
Схема выбора алгоритма может выглядеть следующим образом:

Второй подход работает противоположно. То есть мы можем указать, сколько у нас есть доступной памяти, и попросить cuDNN выбрать алгоритм, который впишется в ограничения.

Когда мы работаем с PyTorch и указываем cuDNN-бэкенд, результаты могут быть не всегда стабильны. Потому что в рантайме выбираются разные алгоритмы. Например, для тестов можно использовать детерминированные алгоритмы и отключить их автоподбор — тогда результаты будут повторяться. Это делается следующим образом:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
Этот подход в нашем проекте мы отложили, потому что хотели, не используя cuDNN, получить свертку, которая сразу работает с помощью одного алгоритма без рекурсии с нужной нам размерностью и оптимизирована по скорости и памяти.
Мы изучили, какие еще доступны реализации. В PyTorch есть cuBLAS-бэкенд. Там реализован алгоритм на основе im2col. В PyTorch он называется slow convolution dilated.

Рассмотрим, как работает im2col-подход.

Мы преобразуем изображение (или другой многомерный сигнал) и соответствующий фильтр (тоже может быть многомерным) в специальные представления в виде 2D-матриц. Далее я буду рассказывать про построение convolution-матрицы, где преобразование фильтра работает существенно проще и представляет собой развертку.
Сначала посчитаем размер матрицы свертки на основе входных параметров. Для этого у нас есть формулы, по которым мы вычисляем размерность результата свертки в зависимости от stride, padding и dilation.

Значение размера результата влияет на горизонтальный размер матрицы свертки. Вертикальная же размерность матрицы свертки зависит от размера фильтра. На рисунке выше видим пример двумерной свертки. Если у нас многомерная свертка, то в размерности матриц включаются дополнительные слои и размеры батчей.
После вычисления размера этой матрицы ее нужно аллоцировать. PyTorch не всегда работает напрямую с CUDA. Вместо нее используется ATen — внутренняя библиотека линейной алгебры. У нее тоже есть бэкенды для разных платформ. В нашем случае это cuBLAS. Здесь мы используем тип at: Tensor, создаем объект columns и изменяем размер его до нужного.

После того, как мы создали матрицу свертки, нужно заполнить ее значениями.

Преобразование многомерного изображения (volume) делается функцией hvol2col, после чего вызывается операция at: cuda:blas:gemm. Здесь это функция библиотеки ATen (AT). Но это просто C++ обертка, шаблон для вызова нужной функции cuBLAS, так как cuBLAS предоставляет C-интерфейс. Для каждого типа (float32, half-precision и других) используются разные функции.
Тут можно еще обратить внимание на макрос AT_DISPATCH_FLOATING_TYPES_AND2. Он нужен, чтобы вызвать конкретную реализацию свертки в зависимости от типа входного тензора.
input — это входной тензор. У него есть метод scalar_type, который возвращает enumeration, сообщающий тип данных. Этот подход работает так:
Функция (hvol2col), которая заполняет convolution-матрицу, делает делегацию к двум функциям: l im2colили vol2col в зависимости от размерности. То есть im2col — это две размерности, а vol2col — три.

В этих функциях происходит вызов CUDA-ядра (kernel). Основное отличие здесь — вызов конкретного ядра и расчет размерности grid, на котором оно будет запущено.
Например, запуск im2col-ядра работает так:

Тут каждый поток отвечает за заполнение той части convolution-матрицы, которая соответствует одному из значений. В зависимости от положения в convolution-матрице поток берет значения из исходных данных:

Допустим, в ядре мы получим положение ячейки I5, которая находится в шестом столбце. Из этих индексов можем рассчитать, в каком месте к исходному изображению был применен фильтр. Затем в соответствии с размерами фильтра пройтись по нужным значениям в исходном изображении и заполнить этот столбец. Каждый столбец в convolution-матрице соответствует одному применению фильтра.
Рассмотрим реализацию самого ядра:

Внутри CUDA-ядра (функции, которая будет запущена в наших CUDA-потоках, как и в первом примере) мы должны вычислить сначала индексы данных, с которыми будем работать, в зависимости от индекса ядра. В PyTorch есть специальные макросы для работы с индексацией. Например, CUDA_KERNEL_LOOP_TYPE, который позволяет получить индекс данных в зависимости от потока.
Этот макрос уже сам обрабатывает 3D-ID. Потому что один поток может обрабатывать один или несколько элементов, а цикл может идти по нескольким индексам в convolution-матрице.
Когда рассчитали начальные индексы, мы вычисляем указатели на данные. col — это указатель на данные convolution-матрицы. im — это исходные данные изображения.
Зная положение в исходном изображении, мы получаем два цикла, которые идут по размерностям фильтра и копируют данные в столбец convolution-матрицы.

Мы рассмотрели реализацию convolution-матрицы для варианта im2col — другими словами, для 2D-случая. Вот как выглядит построение матрицы для 3D-случая vol2col:

Обратите внимание на выделенные строки кода. Видно, что для обработки дополнительной третьей размерности нам всего лишь понадобилось изменить расчет индекса и добавить один цикл по ksize_t. Для больших размерностей подход будет аналогичным.
В работе этот подход требует достаточного большого объема памяти. Однако его легко расширять и поддерживать. Также он показывает хорошую производительность на больших размерностях, если у вас есть запас памяти.
Следующий подход — библиотека Cutlass и применение алгоритма Implicit GEMM.

Подход основан на тайлинге — разбиении задачи на мелкие подзадачи и распараллеливании. Как устроен процесс работы:
Эти настройки также можно конфигурировать с помощью библиотеки. Основная цель — максимально перенести данные для вычислений в регистры процессоров и свести к минимуму операции с глобальной памятью, поскольку они вызывают наибольшие задержки.
Библиотека предоставляет различные уровни специализации и конфигурирования: Device-level, Kernel-level, Block-level, warp, Instruction. Весь API представлен в виде шаблонов, из которых можно набирать те типы, которые потом инстанцируются для реализации нужного тайлинга.
В библиотеке Cutlass уже реализован алгоритм Implicit GEMM на уровне Device-level. Это значит, что мы можем просто вызвать операцию свертки с нужными параметрами. Однако нам нужно будет ее изменить, чтобы увеличить размерность.
Кроме свертки, библиотеку Cutlass можно применить для реализации различных других алгоритмов, основанных на GEMM, — например, attention-блоков для трансформеров, так как это тоже перемножение матриц. В рамках алгоритма Implicit GEMM мы не строим сразу всю большую convolution-матрицу, а наоборот, распределяем построение по вычислительным CUDA-блокам.
На схеме видно, что один блок будет вычислять один элемент матрицы, второй — другой, третий — третий и так далее:

В рамках одного потока мы берем блоки из части матрицы и связанные с ними фильтры, помещаем их в shred-память, а затем в регистры. После этого выполняем быстрое матричное вычисление и складываем с аккумулятором.

У операции Implicit GEMM, которая реализована в Cutlass, есть определенные ограничения. Максимально эффективно она работает при следующих условиях:
Для нас это стало одной из неприятных особенностей. Дело в том, что в PyTorch формат тензоров в памяти — channel-first. И когда мы реализовали Implicit GEMM, пришлось добавить в модели операции транспонирования перед каждой сверткой.
CUTLASS — это набор C++ шаблонов, поэтому сначала нужно сформировать набор типов, которые потом проинстанцируются в объект. Рассмотрим 2D-свертку:

Построение тайлов в CUTLASS реализовано двумя способами:
Дальше мы должны описать тип эпилога (Epilogue).

Эпилог задает операции, следующие после умножения матриц, и определяет, как мы будем работать с аккумулятором. Так как мы перемножаем много маленьких блоков, впоследствии нам нужно будет их сложить (аккумулировать).
Обратите внимание, что в данном примере тип тензора и аккумулятора — это целочисленные значения, то есть четырехбайтный Integer. В CUTLASS можно использовать и Integer, и Floating point-типы, и смешанные типы вычислений.
Дальше надо задать размерности задачи и указать тип математической операции — взаимная корреляция или реальная свертка:

В другой структуре типа Arguments мы прописываем указатели на данные:

Естественно, их нужно предварительно перенести в память GPU и добавить соответствующие указатели.
После того, как мы описали этот тип, мы можем его инстанцировать в виде implicit_gemm_op-объекта:

Следующий шаг не очень очевидный: нужно получить размер дополнительной памяти для этого алгоритма. Откуда он может взяться? Это зависит от деталей реализации выбранных алгоритмов. Например, мы используем второй режим с оптимизацией, когда заранее рассчитываем смещения и сдвиги по всем указателям для заполнения convolution-матрицы. В таком случае нам нужна память под таблицы смещений. И отсюда будет браться этот дополнительный размер, но он существенно меньше, чем для прямого вычисления im2colGEMM.
После чего мы инициализируем операцию и вызываем ее как функтор. В последней строчке будет запущено CUDA-ядро без вызова какой-то слинкованной библиотеки типа cuBLAS.
Нам надо было поменять только объекты итераторов, которые отвечают за перенос значений исходного изображения из глобальной памяти в shared-память.

На следующем изображении красным отмечено, что мы поменяли, а все остальное — это то, что реализовано в CUTLASS.

По сути, это строительные блоки операции GEMM, которые используются для свертки.
Типы, где смещения указателей и маски вычисляются аналитически:
Типы, где указатели и маски вычисляются заранее и используются таблицы:
Итератор работает следующим образом:

Итератор вызывается в каждом CUDA kernel, получает индекс с потока и блока, из них — координаты результата свертки в результирующей матрице (последняя формируется после применения фильтра). У него есть несколько методов:
Визуализировать это можно так (смотрите сверху слева и направо):

Вверху у нас тот же самый пример с изображением 3×3 и фильтром 3×3. Результат — девять значений свертки. Рассмотрим индексацию для результата GEMM с идентификатором o7. Это соответствует координатам в результате свертки y7=[2,0], так как после умножения мы получили матрицу 1×9, но на самом деле у нас двумерный результат 3×3.
Используя приведенные формулы, мы можем перевести все индексы в соответствующие двумерные размерности. Также, зная индексы в результате свертки, можем понять, к какому элементу исходного изображения применялся фильтр.
Точно так мы пересчитываем координаты. Дальше линейно пройдемся по значениям фильтра, получим значения исходных данных и перенесем их в тот блок convolution-матрицы, которая =заполнит нашу shared-память для дальнейших вычислений в реализации Implicit GEMM.
Посмотрим на реализацию этого tile-итератора только для activation:

Activation — это исходный входной сигнал. Объект этого типа класса инициализируем индексом потока и координатами блока, из которых мы получаем две координаты (нас интересуют p и q). То есть это двумерные координаты в результате свертки.
В коде они обозначены как offset_p и offset_q. Мы видим, что есть еще другие offset. Их появление связано с тем, что обычно при реализации сверточного слоя есть какое-то количество входных и выходных фильтров, которые нужны для обработки многомерных тензоров и формирования результата. Для понимания алгоритма достаточно смещений p и q.
Далее, после того как мы инициализировали координаты p и q результата свертки, мы можем вычислить индекс в исходных данных:

Используя координаты фильтра filter_r и filter_s (они изначально равны нулю и будут инкрементироватся) и наши значения stride, padding и так далее, получаем линейный индекс, координаты в изображении [h, w, c]. Смещение в рамках этих итераторов производится достаточно просто: инкрементом нужных нам индексов по фильтру и следующим элементам. Вот пример реализации смещения по фильтру:

И пример смещения к следующему элементу свертки:
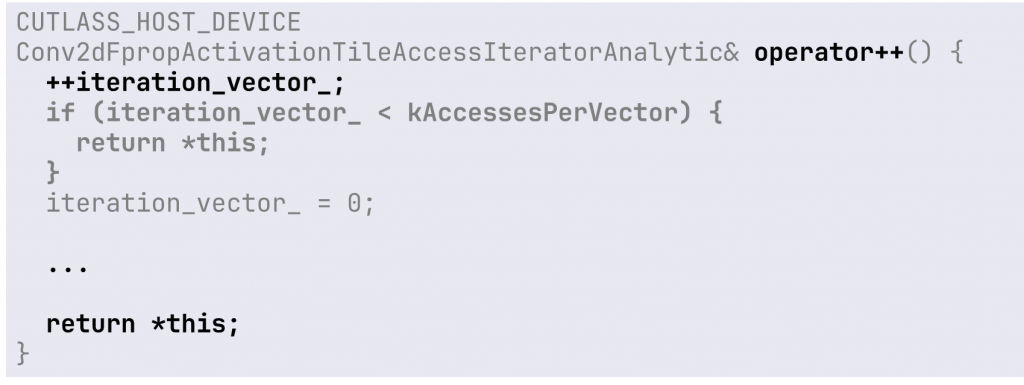
Для перехода к большей размерности нам потребуется только расширить вычисление индексов и добавить циклов. Вот реализация получения координат тензора at в трехмерном ActivationTileIterator:

Все так же, как мы делали с cuBLAS. Мы добавляем еще одну размерность для исходного изображения и фильтра, чтобы вычислить, где находятся данные, используя координаты в выходной матрице и размеры свертки. Такие итераторы легко адаптируются к различным задачам. В CUTLASS приятно то, что нам не нужно переписывать много кода: мы просто используем этот итератор для создания одного из шаблонов для операции GEMM. Остальные части системы остаются без изменений. Это удобно, легко поддерживается и расширяется.
В рамках задачи расширения размерности свертки мы поработали с cuBLAS, с CUTLASS и алгоритмом, основанном на подходе im2col. Он показал очень хорошую масштабируемость, его легко поддерживать и расширять. Используя Implicit GEMM-реализацию, мы смогли работать с исходными данными намного большей размерности, чем GEMM.
Были проблемы с форматом тензоров памяти, потребовалось транспонирование. Это немного снизило производительность и эффективность этой операции, но только в рамках PyTorch. Возможно, если вы реализуете какой-то алгоритм с нуля, это не будет проблемой.
В проекте наше решение вышло похожим на cuDNN — мы сделали динамический выбор алгоритма. В зависимости от размера данных и доступной памяти мы использовали Implicit GEMM или GEMM. Для больших тензоров однозначно подходит Implicit GEMM. На forward pass-работе можно использовать тот же рекурсивный вызов cuDNN. А на средних размерах данных можно эффективно применить GEMM.




