

Изображение создано с помощью нейросети
Вячеслав Пачков, ведущий инженер по разработке ПО в департаменте СХД YADRO, в подробностях раскрывает принципы и процессы, реализованные в T-RAID — технологии защиты целостности данных, которая используется в гибридной СХД TATLIN.UNIFIED, а также СХД для сверхбольших объемов данных TATLIN.ARCHIVE.
Чтобы обеспечить доступность данных, T-RAID решает определенный набор задач. Далее я перечислю их вместе с используемыми в каждой задаче техническими средствами. А затем раскрою подробности реализации каждого из этих инструментов.
Построение пула хранения на несколько петабайт. Эту возможность обеспечивает схема расположения данных в T-RAID, реализация страйпов и allocation-групп дисков.
Оптимизация ребилда дисков и нагрузки на них. T-RAID проводит ребилд только реальных данных, а также распределяет нагрузку ребилда на несколько дисков. Здесь задействована обработка ошибок через блоки, а также фоновые процессы recovery и balancer. В распределении нагрузки помогает фоновый воркер rate limiter и адаптивный троттлер фоновых процессов.
Защита от выхода из строя аппаратных компонентов СХД (процессора, материнской платы, блока питания, контроллера, системного диска). Достигается посредством двухконтроллерной работы в режиме active-active. Тома блоков доступны на запись и чтение одновременно с двух контроллеров при балансировке нагрузки к лунам. Реализацию active-active мы раскроем в отдельной части материала.
Обеспечение отказоустойчивой работы с самими данными от получения запроса до записи в диск. Это реализуется с помощью integrity-механизмов.
Отработка отказов оборудования. Здесь возможно несколько сценариев разного масштаба — от потери отдельного диска до потери целого контроллера или интерконнекта. Эти сценарии мы также рассмотрим далее в статье — в разделах о защите и симметричном кластере.
Перейдем к технической реализации работы T-RAID.
Схема защиты задается формулой k+m, где k — количество блоков данных пользователя, а m — количество блоков данных для восстановления. Схема определяет избыточность рейда, то есть до скольких дисков можем потерять, чтобы в итоге сохранить данные.
Для k > 1 в T-RAID используется код Рида — Соломона (Erasure Coding):
Если k=1, то мы имеем дело с зеркалами, многочисленными копиями данных в рамках пула.
Если ошибка записи возникает на большем числе дисков, чем может покрыть используемая схема защиты, возникает риск неконсистентности. Дальнейший сценарий в этой ситуации зависит от того, превышает ли количество failed-блоков (ответивших ошибкой на запрос записи) значение m.
Если не превышает, то блоки на дисках с ошибкой или даже целые диски помечаются как failed, причем на обеих нодах в кластере. Новые failed-блоки приближают запуск фонового восстановления, увеличивая связанный счетчик incomplete protection.
Если количество failed-блоков в ходе I/O операции превышает значение m, то T-RAID пытается повторить I/O-запрос через соседнюю ноду и в случае успеха переходит к сценарию из предыдущего абзаца.
В сфере хранения данных есть два похожих термина — стрип (strip) и страйп (stripe). Стрип — это объем данных, который мы пишем на один диск, прежде чем перейти к следующему. А страйп — это стрип, умноженный на количество дисков с данными в RAID.
Представим, что наш стрип равен 8 Кб при схеме 4+1. Страйп в таком случае будет составлять 32 Кб, и при запросе на каждый из четырех дисков будет по очереди записываться 8 Кб. Если страйпы у нас большего размера, например, 128 Кб, то запрос на 32 Кб будет разделен иначе. Данные, присланные пользователем, будут записаны на один диск и связаны с parity-данными на другом диске. Чтобы понять, что записать в parity-блоки, нам нужно будет прочитать дополнительный объем данных. Размер страйпа определяет расположение данных на дисках:

Запросы большого размера разбиваются на несколько запросов поменьше и последовательно пишутся на диски. Когда размеры запросов выровнены по страйпу, то операций read/modify/write не будет, поскольку не будет недостающих фрагментов. Мы просто пишем данные и parity-блоки, так что избыточность получится совсем незначительная. Если запись идет более мелкими блоками, чем задано, придется дополнительно прочитать недостающие данные внутри страйпа, чтобы пересчитать parity-блоки и записать их на диски.
Выбирая размер страйпа, стоит учитывать, как мы будем читать и писать данные. Если блоками по 32 Кб, как в примере, то удобнее задать большой страйп: тогда каждый запрос будет обслуживаться одним диском, а не четырьмя. Это особенно актуально для HDD, ведь чем меньше мы их трогаем, тем лучше.
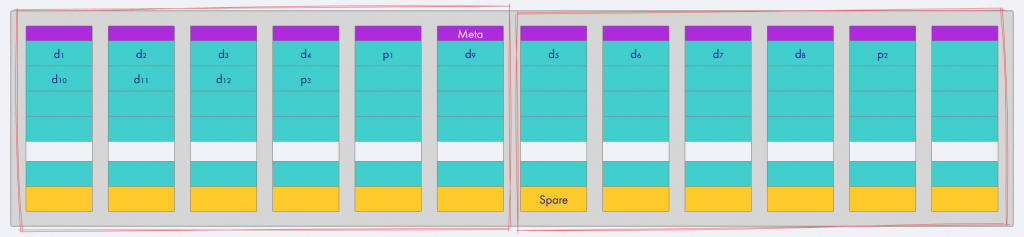
Я рассказал, как устроены стрипы и страйпы, и теперь могу привести пример размещения исходного тома (вверху) в пуле T-RAID (внизу).

Исходный том включает k+m (в данном случае 4+1) аллоцированных блоков по 16 Мб, в которых размещаются описанные выше страйпы. В итоге получается 12 блоков с данными (d) и три parity-блока (p). Далее они распределяются по дискам в пуле. Я специально изобразил в пуле шесть дисков, поскольку схема 4+1 не определяет их точное количество — большее тоже будет нормально работать.
В начале каждого диска в пуле размещен обратный индекс: он содержит информацию о том, какие блоки какого тома где хранятся. Например, первый блок диска — это первый блок четвертой цепочки пятого тома. Карта расположения блоков в томах держится в памяти и синхронизируется с диском, чтобы после перезагрузки системы мы смогли ее снова прочитать. Диск на 14 ТБ вмещает порядка 900 000 блоков по 16 Мб.

Цепочки защиты данных создаются по требованию, то есть при первом обращении к данным.

Эта фича по умолчанию включена только в нашей гибридной СХД TATLIN.UNIFIED. Мы попарно сохраняем чек-суммы для всех соседних блоков в страйпе, и в результате получается цепочка защиты блоков — по сути, упрощенная версия блокчейна. Если в каком-то блоке данные стали нечитаемы, то по чек-суммам мы легко можем понять, какой диск проблемный, и попытаться починить все на лету.
Это может помочь и при проверке данных на консистентность, если в массиве используются диски, которые умеют хранить метаданные, то есть с поддержкой Data Integrity Field. Все диски, что мы используем в TATLIN.UNIFIED, такую поддержку имеют — и NVMe, и SAS HDD, и SAS SSD.
RAID-массив содержит диски, где данные записаны блоками, а блоки состоят из страйпов. Когда дисков в массиве много, две соседние цепочки могут быть частично записаны на один диск. В таком случае диск может стать узким горлышком при записи в том, соответствующий этим цепочкам.
Чтобы свести вероятность этого к минимуму, мы разделяем диски в пулах на allocation-группы, размер которых не меньше, чем размер цепочек защиты. При сборке цепочки T-RAID старается взять все блоки из одной группы, и тогда соседние цепочки используют разные наборы дисков. Так мы уменьшаем вероятность появления боттлнеков, а также возможные проблемы от потери дисков в рамках пула. В результате мы можем потерять до m дисков в каждой allocation-группе — и этот показатель можно умножить на общее число групп, если диски были в разных группах.
Фоновые процессы в T-RAID горизонтально масштабируются через настройку количества потоков.
Recovery осуществляет ребилд массива при потере диска и состоит из трех основных фаз.
Heal определяет максимальное количество поломанных фрагментов данных и пытается снизить его за счет исправления отсутствующих и failed-блоков. При выходе из строя новых дисков во время ребилда heal автоматически переключается на наиболее уязвимые группы аллоцированных блоков, сокращая окно уязвимости данных.
Копии блоков с удаленных пулов heal старается аллоцировать в spare-пространстве той же allocation-группы. Spare-пространство используется в T-RAID вместо spare-дисков, оно распределено по всему пулу, чтобы избежать нехватки пропускной способности отдельных дисков. Если heal не может разместить блоки в той же allocation-группе, это может снизить надежность системы.
Regroup в этом случае приходит на помощь и восстанавливает расположение блоков. Обычно regroup вступает в дело уже после замены проблемного диска и повторного прогона heal.
Rebalance проверяет, что диски в пределах allocation-группы заняты примерно одинаково и подсчитывает, сколько блоков или секторов нужно перенести для восстановления баланса.
Balancer, или внешний балансировщик, отвечает за равномерное распределение allocation-групп по томам. Он проверяет это, последовательно обходя каждый том.
Scrubber проверяет, что в группах аллоцированных блоков данные читаются нормально. Это позволяет избежать stealth data corruption: когда разрешение на запись есть, но данные в секторе были повреждены без нашего ведома.
I/O-операции, вызываемые фоновыми процессами, могут конфликтовать с пользовательскими запросами, поэтому T-RAID разводит их через кластерную, или распределенную, блокировку. Перед восстановлением данных фоновый процесс проверяет, что пользовательские процессы не затрагивают проблемный блок, и только в этом случае начинает работу.
По умолчанию в RAID-массиве каждый запрос на операцию обрабатывается незамедлительно и отправляется в блочный стек на исполнение. Поэтому при большом потоке уже отправленные в блочный стек запросы могут выстраиваться в длинные очереди и вылетать за таймауты низлежащих стеков ОС еще до своей отправки в диск. Так RAID-массив — особенно на основе HDD — будет делать ложный вывод о проблемах с дисками и постепенно исключать их из работы.
Чтобы этого не допустить, в T-RAID предусмотрен rate limiter. Он есть у каждой allocation-группы в пуле. Один rate limiter подключается в момент входа запроса в блочное устройство тома и создает план выполнения этого запроса:
Если суммарная стоимость нового и текущих запросов не превышает заданный порог для allocation-группы, запрос обрабатывается по этому плану. Если нет — запрос ставится в очередь allocation-группы. После исполнения запроса его стоимость снова вычитается из общей стоимости запросов allocation-группы. Если она достигает установленного нижнего порога, rate limiter этой группы пробуждается и продолжает обработку запросов.
Служебные процессы T-RAID потребляют I/O-ресурсы системы, вступая в конкуренцию с пользовательскими запросами. Нам нужно эту конкуренцию минимизировать. Это можно сделать, отдавая больше ресурсов служебным процессам при малой нагрузке от пользователей — и строгом ограничении в обратном случае.
У фоновых процессов изначально уже есть механизм троттлинга, но он требует ручного управления и поэтому не особо распространен. Чтобы его автоматизировать, нужно стабильно опираться на что-нибудь при оценке загруженности системы.
Адаптивный троттлер использует для этого задержки на дисках — это одно из очевидных проявлений перегруженной системы. Он подсчитывает количество медленных запросов с разбиением статистики по периодам и таким образом получает информацию о «длине и толщине хвоста» — максимальной задержке на диске и количестве запросов с такой задержкой.
Далее происходит сравнение результатов с предустановленными показателями. При большом времени ответа троттлер притормаживает фоновые процессы, а при малом — ускоряет их, пока время ответа не достигнет нормальных значений.
Диски в массивах могут периодически выдавать ошибки или даже вовсе отваливаться. Когда диск отвечает ошибкой на запрос записи, T-RAID целиком помечает блок записи на нем как failed. Это значит, что данные в блоке неконсистентны и далее читать из него не нужно.

Если впоследствии при чтении T-RAID видит такие метки, то он на лету обращается к parity-блоку и восстанавливает информацию. Кроме того, появление failed-блоков инициализирует фоновый процесс recovery, описанный выше, в результате которого данные переносятся на другие диски.
Для предотвращения таких проблем T-RAID также отслеживает время ответа от дисков, оценивает их на основе установленных таймаутов. Когда диск начинает медленно отвечать, эти таймауты постепенно уменьшаются, чтобы диск быстрее отвалился. Если у диска накапливается много запросов, не уложившихся в таймаут, его автоматически выкидывают из пула и происходит вызов recovery.
T-RAID работает в режиме Active-Active, то есть пользовательские запросы к дискам обслуживают все storage-процессоры. При старте системы в каждой паре процессоров назначаются роли master и slave, которые могут потом меняться при переконфигурации — например, при загрузке нод.

Различие между master- и slave-нодами только в том, что первая обновляет все метаданные на дисках и включает lock-менеджер, который обслуживает распределенные блокировки. Взаимодействие между нодами происходит через RPC-сервер поверх протокола RDMA.

При поломке master-ноды T-RAID назначает бывшую slave-ноду новой master-нодой, удаляет все блокировки от сломанной ноды и продолжает работу. После перезагрузки бывшая master-нода станет slave-нодой, синхронизирует свои индексы с master и пара снова заработает. Эта процедура называется failover, она проходит довольно быстро, так как T-RAID способен в течение пары секунд узнавать, жива ли вторая нода, с помощью хартбитов на дисках, генерируемых обеими нодами.
Возможна ситуация, когда теряется связь между контроллерами нод в паре. Master-ноде это не мешает. Slave-нода понимает, что связь потеряна и она не может обрабатывать запросы, ведь индекс расположения блокировок не обновляется. В таком случае slave-нода перестает работать, пока не будет уничтожена или пока не восстановится связь.

Обе ноды в паре могут посчитать себя master-нодами — это тоже следствие нарушения связи, такую ситуацию называют split-brain. Она повышает вероятность поломки данных, так как обе master-ноды будут вносить изменения в блокировки и метаданные дисков, не синхронизируя их друг с другом.
Для защиты от такого split brain в T-RAID предусмотрен механизм multiplier modifier protection (MMP) через хартбиты на дисках. В каждом пуле на всех нодах по одному и тому же алгоритму мы выбираем несколько дисков и начинаем раз в некоторый период прописывать там id ноды, ее роль и метку времени. Ноды в паре читают эти данные друг у друга. Если master-нода замечает, что она уже не единственный master в паре, она прекращает работу, роли переназначаются и работа восстанавливается. Эти процессы выходят уже за пределы T-RAID — ему достаточно найти проблему и уберечь данные.
Каждый storage-процессор в паре соединен с дисками своим кабелем. Если один кабель в паре оборвать, диски будут видны только на другом процессоре. Прежде чем отчитаться об ошибке пользователю, отрезанный процессор попытается обработать свои данные через соседа. Так можно будет избежать отказа в обслуживании и недоступности данных, пусть работа несколько и замедлится.
Эта схема работает и для пользовательских запросов, и для метаданных T-RAID. Последнее важно, если провод оборвался у master-ноды: он сохранит способность вносить все нужные изменения в метаданные. После того как соединение восстановят, все продолжит работать как прежде.




Добрый день.
Простите, но что значит в симметричном кластере роли «master» и «slave»? На сколько я понимаю в симметричном кластере обе ноды равнозначным… или должны быть таковыми.
Добрый день!
В симметричном кластере обе ноды работают одновременно и обрабатывают I/O-запросы параллельно. Если одна выходит из строя, вторая полностью берет на себя нагрузку без изменения логики доступа.
В несимметричном кластере — активно обрабатывает запросы только одна нода, а вторая включается только при отказе первой.
Разделение на master-slave нужно для поддержания блокировок и сброс индексов на диски (этим занимается master).