

Изображение создано с помощью нейросети
Инженер Леонид Манеев исследовал некоторые open-source фреймворки — кандидаты на платформу для опорной сети пятого поколения операторского уровня, и решил поделиться своими выводами в этой статье. В ней он сравнивает Seastar, mTCP, Boost.Asio, userver и ACE, рассказывает, почему примитивы синхронизации — это плохо, а затем погружает читателя в глубины Seastar.
Основное требование к платформе опорной сети 5G — справляться с нагрузками. Чтобы от чего-то оттолкнуться, давайте предположим, что опорная сеть должна обеспечивать пропускную способность 100 Gbps user plane трафика и обслуживать 100 тысяч активных пользователей.
Даже при таких невысоких нагрузках сразу становится понятно, что обычным epoll-реактором тут не отделаться. Конечно, можно было бы прикрутить XDP и в итоге выжать даже больше 100 Gbps, однако далее вы увидите, что фреймворк позволяет проще добиваться желаемых показателей, а также предоставляет множество дополнительных плюшек.
Давайте зафиксируем еще несколько требований:
Итак, учитывая вышесказанное, посмотрим, что имеется на просторах:

Первым идёт Seastar с его killer-фичами: share-nothing архитектура, lock-free cross-CPU communication и отсутствием примитивов синхронизации. При этом фреймворк, конечно, асинхронный. Более подробно об этом, а также о шардировании мы поговорим чуть позже.
Следующий инструмент — mTCP. Строго говоря, неправильно называть его фреймворком, скорее это просто userspace TCP stack поверх DPDK. mTCP реализует архитектуру, схожую с Seastar share-nothing, которую сами авторы называют per-core architecture. Не будем подробно заострять внимание на различиях, однако отмечу, что хотя, со слов авторов, mTCP не использует примитивы синхронизации, при взаимодействии между приложением и фреймворком всё-таки полностью от них избавиться не удалось.
…We completely eliminate locks by using lock-free data structures between the application and mTCP. Источник
Например, внутри фреймворка присутствует большое количество мьютексов. Ещё один немаловажный аспект — при разработке опорной сети необходимо наличие основных протоколов, таких как TCP, SCTP и UDP, а также поддержка IPv6. Как видно из таблицы, в mTCP отсутствует практически всё перечисленное.
Далее — всем известный Boost.Asio. Стоит заметить, что данный фреймворк де-факто является стандартом при написании сетевых приложений на C++. У него богатая функциональность и огромное комьюнити. «В коробку» Boost.Asio так и не завезли SCTP. По причине глубоко спрятанного POSIX и желания сохранить устоявшийся API, это оказалось нетривиальной задачей. Как и многие другие, Boost.Asio использует примитивы синхронизации.
Следующий — это userver, фреймворк от Яндекса. Подробнее о его преимуществах можно узнать из этого видео.
Но, говоря кратко, получился действительно мощный продукт с такими фичами прямо «из коробки», как асинхронные драйвера баз данных, трейсинг, метрики, логирование и многое другое. Хотя у userver собственные примитивы синхронизации, более подробно о которых мы поговорим чуть позже, фреймворку всё ещё требуется их наличие. Как и во многих других фреймворках, в userver не завезли SCTP. Важно отметить использование stackful-корутин. Позже мы сравним stackful и stackless корутины, но, забегая вперед, скажу, что для нужд опорной сети больше подходит stackless вариант.
Последний по очереди, но не по крутости — ACE. Подробнее о нём можно почитать тут. Его ключевое отличие от других фреймворков — полный набор функциональности для написания сетевых приложений. В частности, у него есть reactor, proactor, множество протоколов и типов сокетов, реализация connectors, acceptors и много другое. Фреймворк отлично подойдёт для написания опорной сети на основе epoll reactor или создания любого приложения, использующего сетевое взаимодействие. Как и у многих, у ACE есть необходимость в примитивах синхронизации. Каких-то ключевых недостатков в виде отсутствия поддержки протоколов, как у других фреймворках, нет, но, по моему субъективному мнению, к недостаткам можно отнести высокий порог входа из-за не очень дружелюбного API.
Хотя наличие примитивов синхронизации вынесено в отдельный от недостатков столбец, на самом деле этот фактор стал чуть ли не ключевым при сравнении фреймворков. Перечисленные в столбце недостатков пункты, за исключением stackful coroutines, могут быть исправлены, поскольку все фреймворки имеют открытый исходный код, и недостающие элементы можно добавить самостоятельно. А вот избавиться от примитивов синхронизации не получится. Как видно из таблицы, Seastar — единственное решение, которое вообще не использует примитивы синхронизации. Давайте на примере Mutex обсудим, почему это настолько важно.

Ниже представлена сводная таблица, позаимствованная из статьи «Анатомия асинхронных фреймворков в С++ и других языках». В ней представлены результаты замеров, где в бесконечном цикле залочивается и разлочивается мьютекс из разного количества потоков. Сравниваются std: mutex и Mutex из фреймворка userver. В отличие от С++ мьютекса, userver mutex не блокирует std: thread, не переключает контекст и не аллоцирует динамическую память. При всём при том, что Mutex Яндекса избавился от основных проблем, присущих мьютексам, мы все равно наблюдаем overhead в районе 700 наносекунд уже на четырёх потоках. С ростом количества потоков, можно ожидать, что overhead будет всё больше и больше. При этом один из ключевых авторов userver Антон Полухин рекомендует при четырёх и более потоках использовать иные примитивы синхронизации. Но, как будет видно дальше, от примитивов синхронизации можно будет избавиться в принципе.

Если брать стандартный мьютекс, то один из его ключевых недостатков — это переключение контекста.
На картинке ниже представлена довольно известная, хоть и немного устаревшая с точки зрения корректности замеров с учётом современного железа, таблица. На логарифмической шкале представлена стоимость различных операций в тактах процессора: например, простое сложение двух регистров занимает менее одного такта, L1 кэш-чтение — три-четыре такта, чтение оперативной памяти — 100−150. Но самое интересное — это последняя строчка, которая показывает, что стоимость переключения контекста с инвалидацией кэша (при попытке сделать lock на уже залоченном мьютексе как раз произойдёт переключение контекста и, скорее всего, с инвалидацией кэша) огромна и может достигать миллиона тактов, не говоря уже о том, что возникают cache misses. Из этих данных можно сделать предположение, что фреймворк, который работает без примитивов синхронизации и вообще реализован большей частью в userspace, будет на порядок быстрее своих конкурентов.

Если сказанного выше всё ещё недостаточно, чтобы зафиксировать проблемы примитивов синхронизации и мьютекса в частности, то вот тут можно ознакомиться с ещё несколькими аргументами.
Перед тем как переходить к рассказу о том, как Seastar удалось полностью избавиться от примитивов синхронизации, давайте посмотрим на несколько бенчмарков, чтобы убедиться, что выдвинутое ранее предположение о выигрыше за счёт отсутствия примитивов синхронизации действительно рабочее.
Перед тем как переходить к рассказу о том, как Seastar удалось полностью избавиться от примитивов синхронизации, давайте посмотрим на несколько бенчмарков, чтобы убедиться, что выдвинутое ранее предположение о выигрыше за счёт отсутствия примитивов синхронизации действительно рабочее.

Вот первый бенчмарк. На логарифмической шкале представлено сравнение latency на запись в базы данных Scylla и Cassandra. Scylla — это та же самая Cassandra, но использующая в своей основе Seastar. Вообще изначально Seastar разрабатывался Avi Kivity (на cекундочку, прародитель Kernel-based Virtual Machine) и командой как фреймворк для базы данных Scylla. Как видно, сравнивая 99-й перцентиль, Cassandra версии 4.0.0 при 30−35 тысячах записей в секунду держится в диапазоне 5−10 миллисекунд. Тем временем Scylla в том же самом диапазоне latency умудряется писать 170 тысяч. То есть практически в пять раз больше чем Cassandra! Тут можно ознакомиться с множеством бенчмарков Scylla vs Cassandra с подробными выводами.

Второй бенчмарк — Red Panda vs Kafka. Red Panda — это то же самое, что и Kafka, но, опять же, написанное на Seastar. Тут такая же история, что и с предыдущим бенчмарком: пять девяток и далее, Red Panda стабильно держит latency ниже 400 миллисекунд, в то время как Kafka уже при трёх девятках находится на значениях latency 3600 миллисекунд.
После того как стало очевидно, что Seastar показывает невероятную производительность, пришло время ответить на вопрос, как он это делает.
Ключевая особенность, которая позволяет Seastar показывать такие результаты, а также обеспечивает возможность полностью отказаться от примитивов синхронизации — это share-nothing архитектура. Идея заключается в независимой работе каждого ядра (шарда), а также в отсутствии необходимости шарить память между ядрами.

Но как быть, если текущее ядро не владеет памятью, необходимой для выполнения операции? Для таких случаев у Seastar есть высокооптимизированный lock-free cross-CPU communication. Seastar предоставляет удобный API, который позволяет перенаправить выполнение текущей операции на другое (-ие) ядро (-а). Также у Seastar имеется map-reduce. Архитектура share-nothing позволяет получить в первую очередь locality, то есть ядро всегда обращается только к своей памяти. Это в свою очередь позитивно сказывается на аллокациях памяти, кэшах и возможности утилизировать архитектуру NUMA. И, наконец, то, о чём мы так много говорили — примитивы синхронизации не нужны, ведь каждое ядро самостоятельно и в чужую память не ходит.
Стоит заметить, что подобная архитектура требует балансировки нагрузки между ядрами, ведь если одно ядро будет принимать все входящие соединения, то от share-nothing толку не будет. Хорошо, что Seastar предоставляет «из коробки» три механизма балансировки:
При выборе данного метода у клиента появляется интересная возможность: если он знает количество шардов сервера, то может подобрать свой порт таким образом, чтобы соединения всегда приходили на определённый шард;
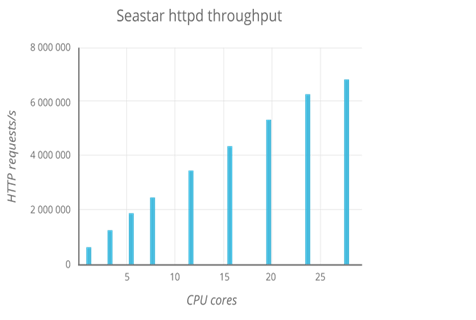
В самом начале статьи, наряду с остальными требованиями, мы зафиксировали желание «из коробки» масштабироваться по количеству ядер. На графике ниже видно, как благодаря share-nothing в линейной зависимости от количества ядер растёт количество HTTP-запросов в секунду.
Пришло время более подробно поговорить о том, что умеет Seastar с точки зрения сетевого программирования. В конце концов, мы его рассматриваем как платформу для написания опорной сети 5G.

Seastar предоставляет два стека. Первый из них — POSIX, реализованный в трех бэкендах: linux-aio, epoll и io_uring. Крутой особенностью реализации является общий API, что означает бесшовный переход между бэкэндами. Более того, делать это можно прямо из командной строки. Допустим, вы написали приложение под epoll, а потом решили, что хотите переключиться на io_uring. Вам будет достаточно при запуске приложения в командной строке указать:
Ваше приложение без дополнительных усилий начнёт работать под io_uring. По умолчанию используется linux-aio, если он доступен.
Второй стек — так называемый Native, реализованный поверх DPDK, Vitrio, либо Xen. Не будем вдаваться в подробности этого стека, лишь заметим, что используется не upstream-версия DPDK, при этом изменения, насколько известно, не драматичные. А ещё при выборе DPDK в сочетании с Poll Mode Drive Seastar будет утилизировать 100% CPU.
Давайте перечислим ещё несколько плюшек Seastar, которые позитивно сказываются на сетевом программировании и не только:
Теперь давайте более подробно рассмотрим, как Seastar утилизирует процессор и память. По умолчанию приложение, написанное на Seastar, забирает все доступные ядра (это можно конфигурировать вплоть до запуска на одном ядре), выделяя по одному потоку на ядро, и всю доступную оперативную память (что также можно конфигурировать), равномерно распределяя её по всем доступным ядрам. При этом память распределяется не рандомным образом, а с учётом NUMA-архитектуры, то есть каждое ядро получит ближайшую к себе память. Этого прекрасного свойства Seastar добился путём переопределения функций аллокации и релиза памяти. Иными словами, у Seastar свой собственный heap memory management.


В этом месте правильно будет упомянуть о недостатке Seastar. Чтобы он эффективно работал, ему надо выделить ядра целиком. Если этого не делать, он будет функционировать, но не так резво, как мы бы хотели. Следовательно, в облачном окружении может просто не быть такого контроля над CPU. И в целом, пожалуй, будет корректно заметить, что не каждое приложение способно утилизировать share-nothing design.
Теперь снова о хорошем. Seastar молодец ещё и тем, что все его примитивы — preemptive, то есть задачи не застревают на выполнении, позволяя эффективно утилизировать асинхронность фреймворка. Что же делать с собственным кодом, выполнение которого может потребовать много процессорного времени, например, с циклом на много итераций, подсчётом хэшей, компрессией и тому подобным? Для этого есть maybe_yield — просто вставляете его в потенциально толстый кусок кода, и Seastar, если понадобится, сам будет вытеснять эту потенциально ресурсоемкую задачу.
Вся асинхронщина ложится на концепцию future-promise. Но это был бы не Seastar, если бы просто использовались std: future и std: promise, ведь, как известно, они блокируют поток. Авторы Seastar c его share-nothing архитектурой и отсутствием примитивов синхронизации этого допускать не хотели, поэтому реализовали собственную пару Future-Promise, которая не блокирует.

А еще разработчики Seastar — адепты современного C++, прямо как мы и хотели, формулируя требования в начале статьи. Как только в C++20 завезли корутины, авторы фреймворка сразу же адаптировали их с учётом всё того же share-nothing и отсутствия примитивов синхронизации.
Давайте отвлечёмся от Seastar и вспомним, почему многие так любят корутины. Для этого на двух фрагментах кода ниже представлен простейший пример асинхронной функции сonnect.
Сonnect using continuations:
Сonnect using coroutines:
На вход функция connect принимает имя, по DNS резолвит в адрес, коннектится по этому адресу и логирует. Казалось бы, проще не придумать, однако даже на этом примере видно, как continuation’ы раздувают код, его становится тяжело читать, на ровном месте появляется тройной уровень вложенности лямбд, а лямбды — это необходимость явно захватывать переменные, что часто приводит к ошибкам типа use-after-move и так далее. В то время как реализация на корутинах представляет собой линейный код, как многие привыкли писать в обычных синхронных программах. Но нужно использовать операторы co_await, co_yield и co_return. А ещё разработчики Seastar заявляют, что производительность при написании на корутинах увеличивается на 10−15% за счёт меньшего количества динамических аллокаций. Так что наличие корутин во фреймворке не может не радовать.
Пришло время заглянуть поглубже в Seastar и обнаружить там несколько интересных моментов. В первую очередь, у Seastar stream-based SCTP, то есть используется тип сокета SOCK_STREAM. С этим можно жить по принципу TCP: писать former’ы, которые будут «кормиться» пакетами, пока не сформируют одно полное сообщение и передадут его клиенту, а затем снова будут «кормиться» пакетами, и так далее. Другими словами, это некоторый механизм, который в потоке байтов определяет начало и/или конец сообщения. В случае TCP выбора нет, работаем как всегда.
С SCTP иная история, ведь он предоставляет встроенные механизмы определения конца сообщения (даже для stream-based сокетов), а именно флаг MSG_EOR, который и означает конец сообщения. Можно по-разному добиться посылки этого флага SCTP-стеком, в зависимости от socket API, который используется для отправки и принятия сообщений. Однако Seastar по умолчанию не предоставляет возможности включить отправку данного флага. Более того, помимо этого флага, также хочется получать MSG_NOTIFICATION, чтобы контролировать состояние SCTP association, а ещё Stream ID, Stream Sequence Number и Payload Protocol ID. Чтобы получить контроль над всем этим добром, в Seastar было добавлено два POSIX-вызова: sctp_sendv и sctp_recvv, а также несколько sockopts: SCTP_RECVRCVINFO, SCTP_INITMSG и SCTP_EVENT. Последние два имеют возможность настройки со стороны пользователя значений этих sockopts. Например, нам интересно контролировать поля sinit_num_ostreams и sinit_max_instreams для sctp_initmsg. Вуаля! Теперь у нас есть более тонкий контроль над SCTP, и формеры не нужны.
Следующий интересный момент: у Seastar есть сущность server_socket, которая фактически является обёрткой над listening-сокетом. У этой сущности есть метод abort_accept, который, как и следует из названия, предназначен для остановки принятия новых соединений. Данный метод реализован для TCP и SCTP одинаково — внутри вызывается POSIX shutdown с флагом SHUT_RD. А теперь прикол: в случае TCP всё работает как и ожидалось, но в SCTP стек вернёт ENOTSUPP (Operation not supported), который Seastar радостно обернёт в исключение и кинет вам.
Пожалуй, грешить на Seastar не стоит, ведь он просто передаёт управление в Linux, и будь что будет. Но сам факт, что дефолтный Seastar API стреляет тебе в ногу на ровном месте, достаточно забавен. Костыльный вариант решения проблемы — вместо вызова abort_accept дёргать деструктор у сущности server_socket. Вроде работает.
Ну и напоследок, три бага в классе WebSocket. Впрочем, класс находится в пространстве имён experimental, так что не будем особо критичны к Seastar. Первый баг связан с последовательностью вызова деструкторов у сервера и его соединений — сначала, конечно, надо релизить соединения, а уже потом север. Два других связаны с формированием header size & value при отправке данных. По RFC-6455 payload length & value заполняются по-разному, в зависимости от размера буфера. В Seastar об этом знают, однако случился своего рода off by one error — вместо length = 4 выставили 3, а вместо value 0x7f выставили 0x7e.
Ну и напоследок чуть-чуть холивара, чтобы было о чём поспорить в комментариях к статье. Выше я упоминал, что userver использует stackful-корутины. Давайте сразу зафиксируем, что это не хорошо и не плохо. Просто для нужд опорной сети stackless подходит больше, и вот почему.
В таблице ниже представлены преимущества и недостатки обоих вариантов.
У stackful-корутин есть два жирных плюса. Первый — отсутствие необходимости как-то менять код: никаких тебе операторов co_*, не надо весь путь промазывать future. Второй — stack-based memory, то есть память для coroutine frame не аллоцируется динамически.
Однако второе преимущество является и главным ограничением stackful-корутин. У стека фиксированный размер, составляющий в среднем 2 MB, следовательно, можно спавнить ровно столько stackful-корутин, сколько доступно стека. А ещё нельзя оптимизировать размер coroutine frame, поскольку заранее неизвестно, сколько понадобится памяти. Вдобавок к этому происходит переключение контекста, и это плохо.

Перейдём к stackless-корутинам. Их, в отличие от stackful, можно спавнить огромное количество, так как для аллокаций используется heap. А ещё у stackless-корутин меньше overhead, в том числе по причине тонкой настройки количества выделяемой под coroutine frame памяти, а не фиксированный кусок, как для stackful. Плюс отсутствует переключение контекста. Из недостатков, конечно же, сам факт наличия динамических аллокаций. Однако компиляторы, зная, что они работают с корутинами, могут использовать разные оптимизации и аллокаторы, заточенные для выделения памяти под coroutine frame. Ну и необходимость использовать операторы co_await, co_yield и co_return, а также промазывать весь путь future.
На этом я заканчиваю погружение в Seastar и приглашаю обсудить в комментариях, является ли выбор данного фреймворка наиболее правильным решением для реализации опорной сети пятого поколения операторского уровня.